
广告激活归因服务的思考
1. 总述
应用激活服务本身就是一个“小蝌蚪找妈妈”的过程,他的业务场景很有特点:写远大于读,历史数据会快速膨胀。应用激活常用的是末次归因策略。整个架构设计相对简单一些,主要是数据存储层和监控告警这两块要认真搞。 整体的思维图: 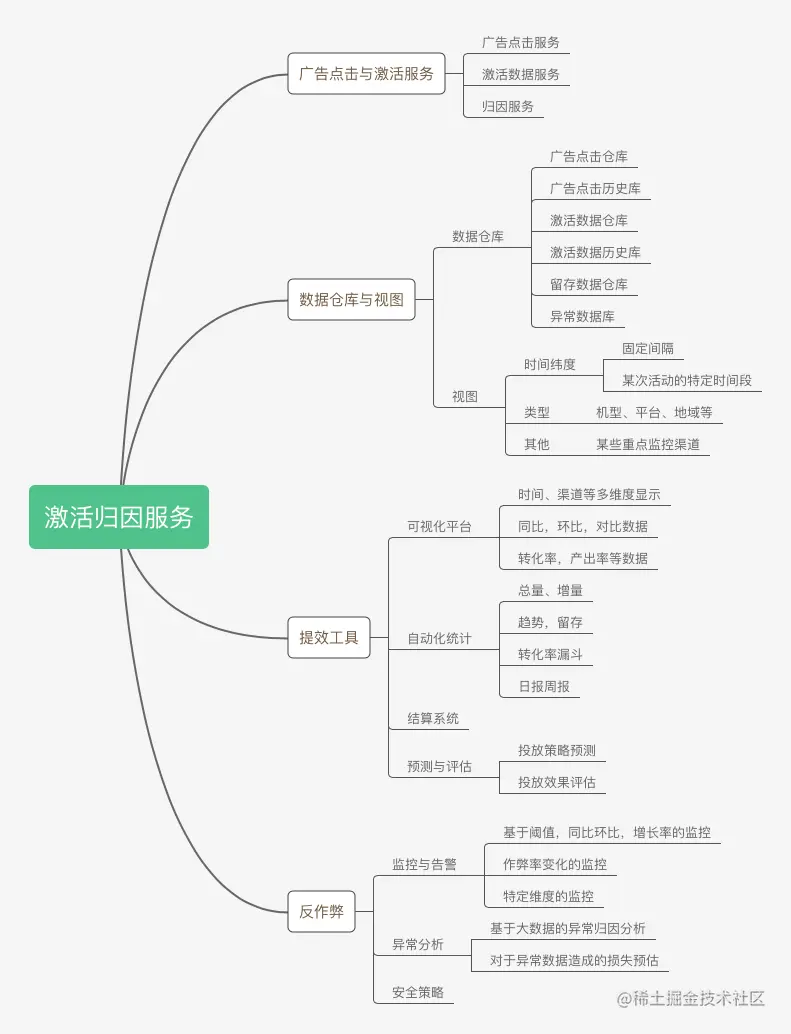
2. 业务简介
2.1. 广告激活归因服务的社会背景
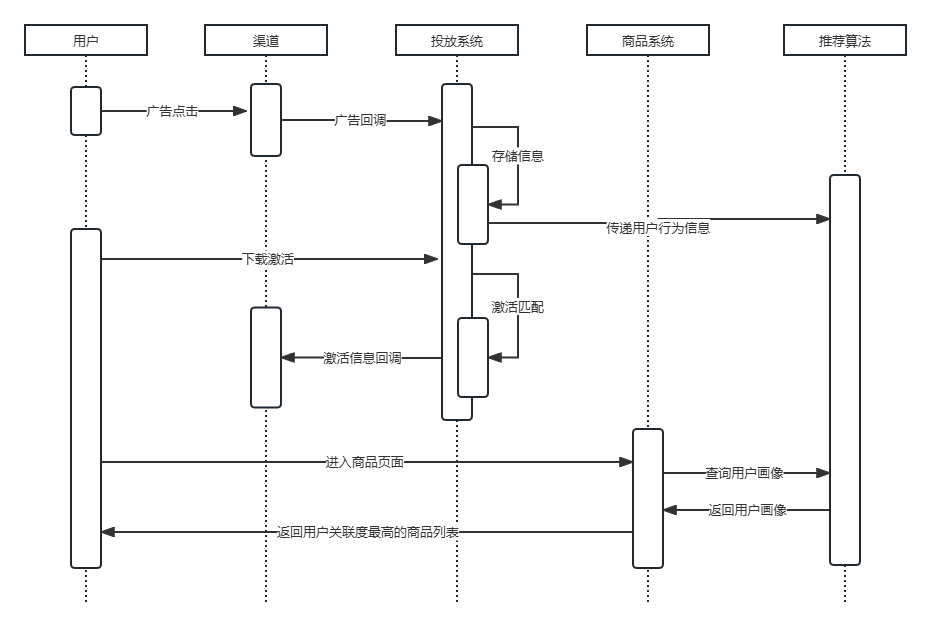
广告行业自古有之。到了互联网时代,这个行业在形式上天翻地覆、千变万化,本质上没有任何改变:提高曝光度,吸引更多用户。激活归因服务只是广告服务里一个小分支,属于较边缘的服务。这个服务的主要功能是:判断一个设备激活行为是不是首次激活;通过设备ID判断这个设备是从何而来。一言蔽之,这是一个“小蝌蚪找妈妈”的过程。 他的整个流程如下:
2.2. 常见的设备ID
我们简单介绍下设备ID,从种类上来讲可以分成两类:
重要
- 设备ID:IDFA IMEI AndroidID
- 广告追踪ID:CAID OAID
详细介绍:
- IDFA,广告主标识符。是APPLE向用户设备随机分配标识号,基本可以保证唯一性,即一个设备号对应一个设备。这个ID 可以关闭,可以重置。IOS14以上版本会逐步关闭,导致获取不到IDFA。
- IMEI,国际移动设备识别码,相当于手机身份证号。双卡双待的手机会有两个IMEI号。Android10以上 也不能获取到IMEI了。
- AndroidID,在Android8以后发生了改变: 第一,如果用户安装APP设备是8.0以下,后来卸载了,升级到8.0之后又重装了应用,Android ID不一样; 第二,不同签名的APP,获取到的Android ID不一样。
- OAID,是安卓的广告标识符,一种非永久性设备标识符。使用OAID可在保护用户个人数据隐私安全的前提下,向用户提供个性化广告。目前国内手机厂商基本都接入了OAID,三星这些并没有接入。国内市场上大约有20%-30%的设备无法获取OAID。
- CAID,与安卓的广告标识类似。目前正在推广,各大知名APP都在接入CAID。覆盖率正在逐步上涨。
2.3. 具体投放归因的方式:
- 基于设备号:精准度较高,但Android10以后获取不到IMEI;Android8以后,Android_ID夸应用不一致;IOS14以后逐步废弃IDFA,或者用户关闭广告追踪。
- 基于渠道号:即针对安装包进行不同的编号。精准度很高,但仅限Android用户;安全性很差,容易被劫持;需要花费大量人工操作。
- IP+UA+Model:准确率较低;多数设备的IP出口一致、UA重复度很高。只能用来做兜底。
- IP+UA(+剪贴板:马蜂窝提出的方案。准确率没有经过校验。
- 基于广告追踪ID:在合适的窗口期内,准确率较高。缺点是需要接入三方服务;市场覆盖率没有百分之百;
2.4. 常用的归因策略
- 渠道包归因策略: 这个方案只能是安卓平台采用。国内的较大规模的广告平台和手机应用商店,线下地推,预装等主要采用这种方案。广告主为不同的渠道打不同的渠道包,以最终激活来源于哪个渠道包来评估流量渠道的效果。这个方案存在较大的安全风险,一方面是安装包可能被人刷量,另一方面很多手机的安全策略会拦截安装包,通过UI来引导用户下载其他安装包。
- 末次归因策略: 市面上最常见的策略,各大广告平台都支持该策略,也是IOS端常用的归因策略。这个策略强调的是最后一次广告点击行为,几个场景:假设用户在不同的平台点击了多次广告,最后下载并激活了我们的APP,那么根据这个逻辑,只会匹配到用户的最后一次广告点击行为,之前的点击没有任何效果和收益。这个策略有一个风险点:可能会有人通过模拟广告点击行为来作弊,在大平台上技术门槛很高,较少见。
- 曝光归因策略: 国内很少见到这个策略,几乎没怎么用过。这个策略是末次归因的放大版本,不仅仅是用户点击行为,用户观看行为也算在其中。这个策略非常的霸道,对广告主很不友好。
- 助攻归因策略: 正常场景下,用户观看很多次广告才会点击一次,点击很多次广告才可能有后续的下载激活行为。假如按照 末次归因策略那么只会算最后一次广告点击为有效。这显然不太符合实际场景。具体的规则目前没有统一,基本上各家有各家的算法。快手和抖音的短视频广告目前就有这种归因策略。
参考: 【再说广告归因】强行将“助攻”算做“直接得分”,还要不要脸? - 知乎
3. 架构设计
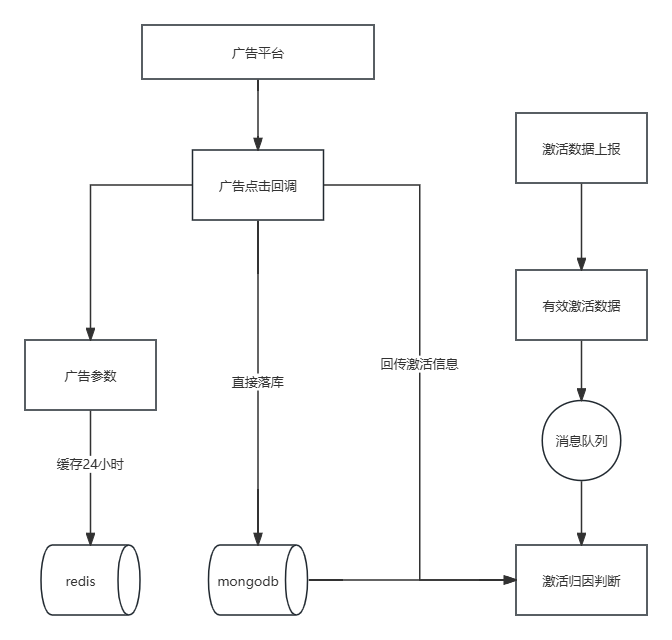
3.1. 激活归因服务核心流程
3.2. 业务场景与特点
激活归因的业务场景非常的单一,结构很简单。基本就是收集广告平台的数据回调,把激活数据和这些数据进行比较,找到匹配数据,再把数据返回给广告平台。总结一下: 数据并发写入请求较高,数据具有时效性且过期无效 写远远大于读操作,且没有读写一致性要求,实时性也不高 历史数据会快速膨胀 服务的可靠性有强要求 另外还有一些这个行业特殊的细节: 市面上广告平台腾讯,头条,快手,百度,新浪,B站等他们的广告回调文档,接口,规格都不一样,整体逻辑相同; 业务的独立性很强,与其他主业务有少量交集,只与数据中台有较强依赖。
针对这些特点我们基本上可以做一个简单架构: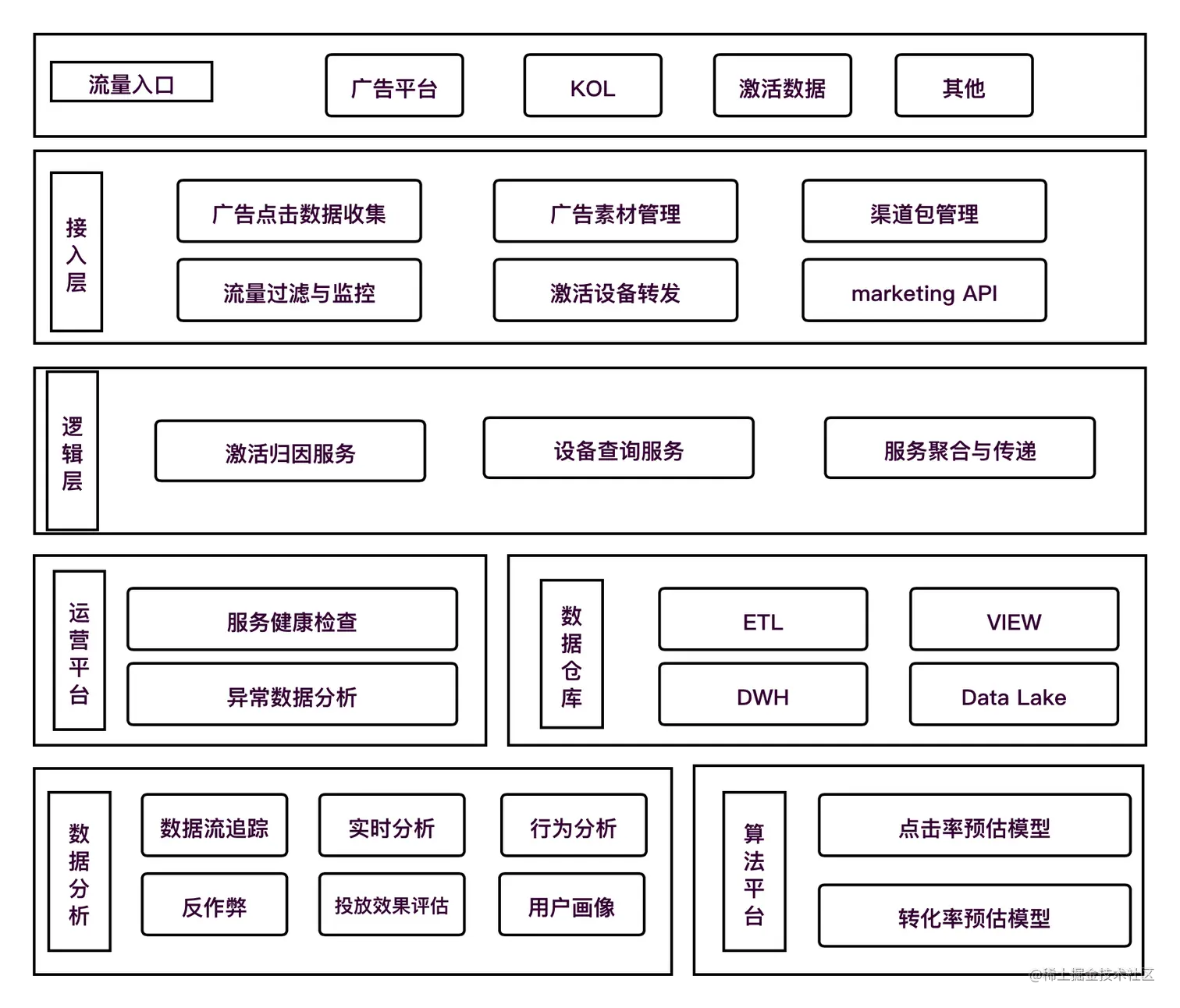
业务的发展和服务的扩张基本上是按照自上而下的顺序来迭代开发。
3.3. 架构设计的注意事项
3.3.1. 存储层的选择
存储层的设计和选项需要考虑两点: 1. 接入层便于快速接入渠道方(支持抖音,快手等广告回调); 2. 历史数据的快速增长; 一般情况下,接入层的会直接采用mongoDB,便于快速开发。历史数据初始阶段采用MySQL分库分表或者按照日期、渠道进行拆分,单库容纳200W激活数据;后期直接换ES 或者接入数仓,将数据集中管理。
3.3.2. 历史设备信息
历史设备信息的存储,一般都是直接丢在缓存里,这块数据量听着很大,其实没多大。一天百万,一年也不过4亿数据量,32GB的redis就够用了,做好数据备份和预热方案就好。 这样做的好处是每次只需要O(1)。也可以采用布隆过滤器的方案,成本稍微高一点。
3.4. 激活归因服务与其他业务线的关系
激活归因服务天生具有极强的独立性,他本身几乎不和任何其他业务线有强耦合。如果出现激活归因服务依赖于其他业务线,结局一定是巨大的灾难。我们在设计时要充分考虑:
首先,服务设计的时候要划分好明确的边界,保证核心服务可用是第一目标。也就是说我们服务本身是为了做激活归因,附带着我们也收集到了应用的装机量,激活量,激活来源,广告投放细节等数据。这些数据非常有用,非常敏感,可以基于他们做很多很有价值的需求,场景还原,丰富用户画像或者进行广告相关的预测分析。但这些进阶需求都不是激活归因服务的核心,我们的核心只需要做好两件事:
重要
- 这次激活信息是不是首次激活
- 这次激活信息是从哪里来的
其次,提供两组接口,一组用来提供简单的数据查询服务,另一组用来对接受一些简单的指令。数据查询服务可以给兄弟服务提供一些业务支持,指令接口用来检测服务是否正常,并对一些开关性质的指令进行相应。最后,需要合理设计服务内的数据流,便于出现问题的时候快速排查,提高服务可用性。另外,数据流一旦涉及到其他业务线,排查起来会非常非常的痛苦。
正常情况下,我们的服务会呈现出非常清晰的调用关系:
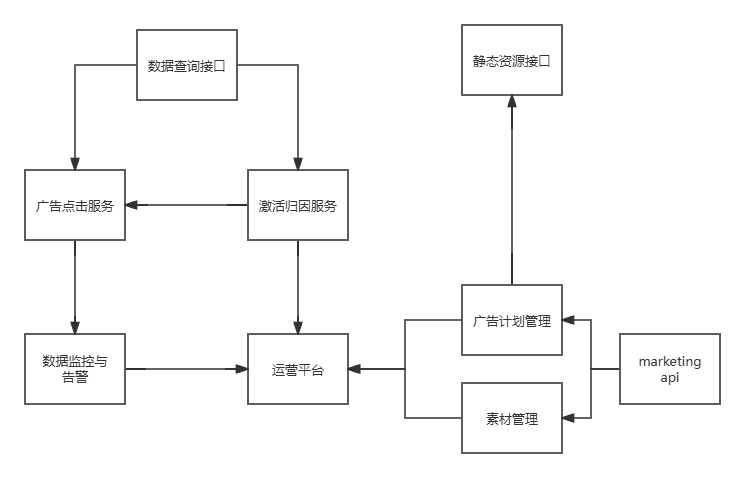
4. 保证服务的可用性
我们这里不多聊跨机房备份这种设计,一般情况下,很少很少会遇到这种极端情况。
根据实际经验总结,保障服务可用性主要是三个方向:
提示
- 数据的量化与可视化
- 日志
- 监控与告警
4.1. 量化与可视化
数据的量化和可视化是基础功能,大多数异常情况都能通过可视化体现出来。量化相对而言简单点,原则上就是MECE原则(不重不漏),服务的技术指标和业务指标都要进行量化和可视化。在技术指标上要重点观察接口的QPS和失败次数,以及DB的调用情况,缓存的命中率等。业务上的指标相对麻烦些,总结下来主要有:
- 单一数值指标没有可比性,主要是观察数据的变化趋势和对比
- 统计的分类越细越好
- 不同的图表展示的信息不同
- 对于重点渠道要重点展示
4.2. 日志
日志的话主要是两块:网关日志和数据周转日志。网关日志在特殊场景下有大作用,可以作为备用数据,在存储数据丢失的情况下,做紧急恢复。数据周转日志,可以在排查数据的时候用来锁定问题。
4.3. 监控与告警
监控和告警相对简单点,可以随着业务逐步完善。把之前的经验总结下:
- 把异常分类,然后梳理一下异常的原因和细节
- 对于趋势图的变化要重点监控
- 异常问题一定是收敛的,记录好异常信息和处理方案,保存案发现场,后续可以进一步升级
- 业务方普遍对于数据的变化是后知后觉的,因此技术方需要做到先于业务发现问题 并分析问题。
- 搭建统一告警可视化平台,对每一条告警信息追踪处理。