
缓存雪崩的解决方案
1. 问题介绍
缓存雪崩是分布式系统中常见的缓存失效问题,指的是 大量缓存数据在同一时间段内集中失效或缓存服务整体不可用,导致原本由缓存承担的请求压力瞬间转移到后端数据库或服务,造成数据库负载过高甚至崩溃,最终引发系统级故障的现象。
重要
就是缓存失效,请求大量压到了 DB 上导致的服务崩溃。
雪崩跟击穿最大的区别:击穿是个别 Key 过期,雪崩是大量 Key 过期。导致雪崩的问题有很多,我们可以捋一捋:
- 如果击穿问题比较严重,会拖累整个服务,进而引发雪崩
- 数据大面积过期,引发雪崩
- 缓存服务出现故障,比如网络抖动、机器故障、请求积压等等
总而言之,就是缓存服务这会不能用了……
相关信息
缓存雪崩很少见的,这个问题的重点是预防,不是补救。真雪崩了,服务基本是也就已经挂了。
2. 解决方案
2.1. 给缓存加一个随机过期时间
这是一个专门解决过期时间相同导致的 雪崩问题,实际上这也是最积累的方案,我们一般不会用。先看下代码:
// 这样写是不行的,最后的参数不会是time时间戳
dt := 5 + rand.Intn(5)
_ = db.Rdb.Set(context.Background(), key, cache, time.Second*dt).Err()
//正确写法
dt := 5 + rand.Intn(5)
sec := time.Duration(dt) * time.Second
_ = db.Rdb.Set(context.Background(), key, cache, sec).Err()为什么不用?因为过期时间相同导致的雪崩,是最最少见的现象,对于核心缓存一般会采用不过期的方式,异步更新,因此多数情况下不会有这种现象。
2.2. 使用多级缓存
参考击穿中的实现
2.3. 使用单飞
参考击穿中的实现
2.4. 接口降级
提示
其他的解决方案都是预防为主,唯有此方案是真的能在发生雪崩时,救人命的方案
我们看下这个图,一般情况下,公司的整体服务都长这个样子:
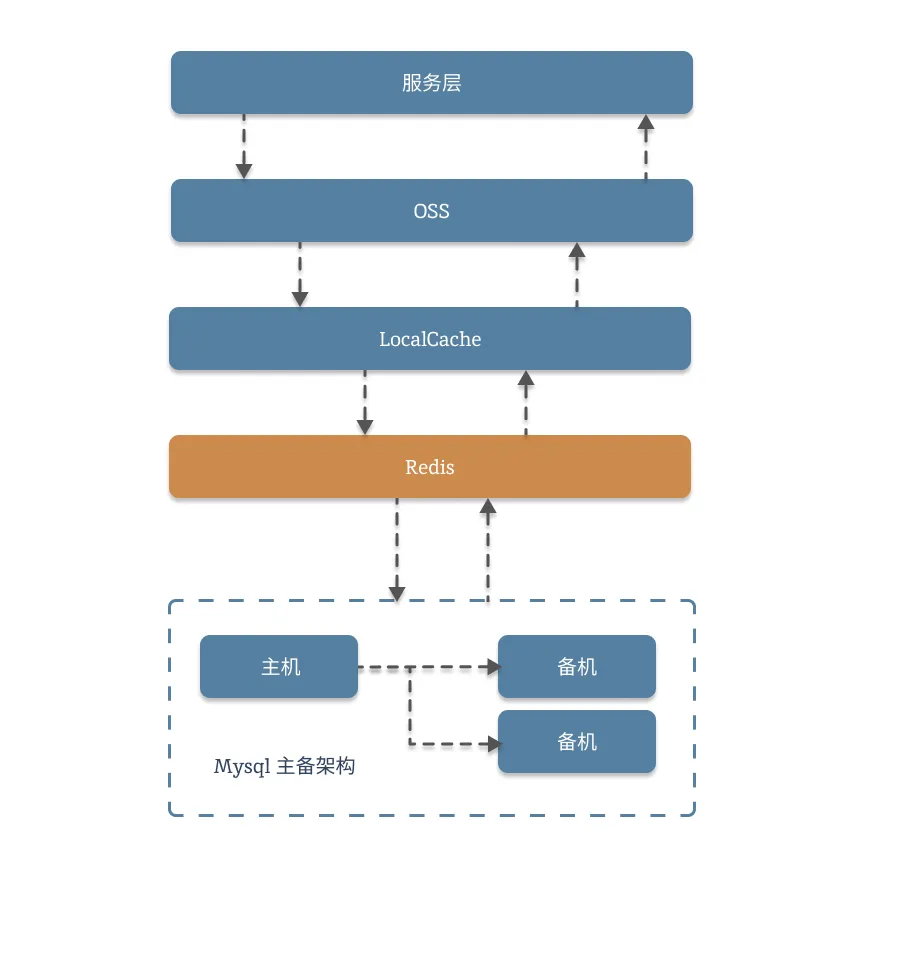
越靠下的组件,越需要保护。就像搭积木一样,越靠近底部,被依赖被调用的就越多,一旦出事故就会拖累整个服务。作为业务方,我们很难主动去优化底层的一些组件,比如数据库,缓存或者其他一些组件。我们能做的只有在尽可能的范围内,使用已有的组件,加固,强化,拼装,冗余现有的服务,以满足服务的健壮和容灾。在底层存储出现动荡的时候,依然能提供一定的服务,不至于将重大事故弄得满城风雨,人尽皆知。
警告
有些大厂对于这类事故的处理非常严格,除了基础部门要背锅,业务部门最后恢复服务的项目组也要分锅。
3. 注意事项
3.1. 关注缓存的命中率
提示
命中率 = 从缓存中直接读取次数/总请求次数
命中率这个指标是整个缓存监控中最重要的指标,它直接影响整个缓存服务的性能和消耗。我们之前聊过,缓存的作用主要是两个:加快响应效率,保护 DB 流量。 命中率的高低就体现了整体服务是否完整的实现了这两个功能。
通常情况下,缓存率至少要 80%以上,缓存服务才算正常,极端情况下甚至需要 95% 以上才行。这也就意味着,缓存的容量要大致与 DB 的热数据量相当。
如果命中率较低,缓存可以认为几乎无效。举个例子:假如 100 的 QPS,命中率在 80 左右,走缓存的 QPS 是 5ms,走数据库回源是 10QPS,那么平均 QPS 为 24ms。如果命中率下降到 60 左右,平均 QPS 为 43ms,看上去没差多少,实际上已经差了将将一倍了。这是非常夸张的情况。
这里又引出一个新的知识点。实际开发中,我们不仅要关注平均 QPS,还要关注 QPS 的 TP99。
相关信息
引申:什么是 TP99
最后,我们举几个缓存命中率的几个例子,说明下情况:
- 命中率过低:一般是缓存方案设计的不恰当,需要结合业务情况改下缓存方案。
- 命中率突然降低,并逐渐回升:一般是出现了一些问题。比较常见的是击穿。
- 命中率出现锯齿状:反复出现击穿问题,需要结合业务修改缓存方案。
- 命中率过高:需要观察此时缓存的内存使用率。如果低于 80%,此时服务处在较好的运行状态下。如果高于 90%以上,存在一定风险,需要做好扩容准备。
3.2. 冷重启与缓存预热
冷重启,其实就是缓存服务停止后,再次启动,此时缓存里没有任何数据。如果此时直接连上服务,并不能承担好缓存的责任,绝大多数的请求还是会回源到数据库,导致服务再次故障。这其实是雪崩问题的困境,出现崩溃后,无法快速恢复服务,贸然重启只会导致服务启动再崩溃,让服务做“仰卧起坐“。
此时,就需要缓存预热。
重要
什么是热重启?也叫不关机重启,一般只是改一些配置的时候会用。
缓存预热的方式又很多种,这里一般会用两种思路。第一种,使用 ADF 和 RDB 混合恢复。因为 RDB 和 AOF 各有特点,并且 各自覆盖一部分情况,所以会混合着使用。如果持久化文件存在一些缺失,可以使用修复命令先修一下内容,再恢复。这里需要注意一点,一般会优先使用 AOF,缺失的话会使用 RDB,**而且这个加载过程是阻塞的,**时间可能会很久,此时 Redis 是无法正常使用的。
提示
AOF 一般都会开启混合模式,能提高效率。(本质上就是 AOF+RDB)
第二种方法是一种应急方案,通过开发人员自己编写脚本,先把热点数据加载进去,覆盖 当前多数流量之后,直接使用。本质上还是一种二八法则,只能拿来应急使用。如果对当前情况判断失误,仍有可能导致服务出现”仰卧起坐“的现象。所以,慎用。
总结
缓存雪崩的危害非常严重,补救措施也比较少,通常还是要以预防为主。常用的方案其实和击穿高度相似,比较依赖服务的整体架构。不同点在于可以使用随机缓存时间的方案来解决缓存同一件时间一起过期的现象。
我们通常会在网关层加上一个降级方案,保护部分接口,使其出现雪崩等问题时,不会影响用户的体验。除此以外,我们需要特别关注缓存的命中率,如果命中率较低,说明当前缓存的内容和数量可能不足以满足业务需要,有可能出现技术上的雪崩问题。
最后,如果真的出现了雪崩。当服务重启需要恢复现场的时候,也不能把缓存重启,然后直接使用。此时缓存内容为空,依然没有起到缓存的两个核心功能。因此需要做一下缓存预热。