
Eino 的源码学习感悟
提示
不要用传统开发的思维来理解 智能 Agent 的开发,也不要用传统框架的思想来理解 Agent 框架。
1. 前言
想要看明白 Eino 的源码,需要三个前置工作:
- 有一定的 LLM 项目开发经验,对于常见的关键词有一定的了解。
- 十分熟悉 Go 语言,对于泛型、接口、并发等有深刻的认识。
- 对于软件工程、代码架构等有一定的了解。
2. 知识地图
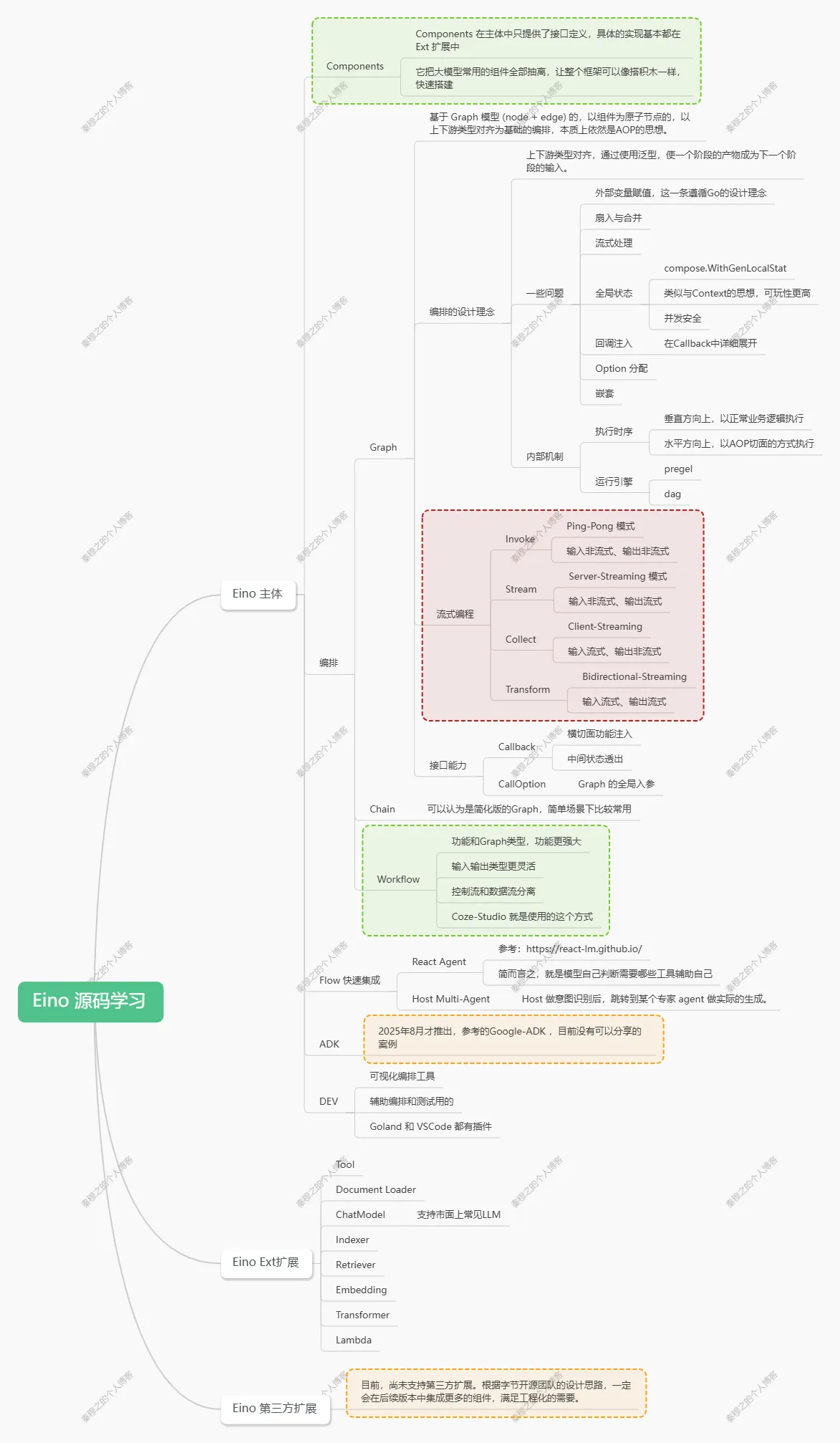
这个图只是一个简图,更详细的内容可以参考:
https://www.processon.com/mindmap/6899667045c93924b0a3fcfb
3. 技术优势
3.1. 对比 Python 框架:
我认为可以拿出来聊聊的主要还是两个。一个是高性能优势,作为原生 Go 实现的框架,能利用协程并发优势,可以提高效率。 但,就目前的源码来看,并发这一块还有优化的空间。另一个,则是严格的类型检查,可以利用 Go 的泛型机制,在上下文传递的时候更准确,更便于大型项目的开发。
总而言之,短暂使用过 LangChain 之后,我们很多同事和朋友都准确的表示,不出一年 java 和 Go 应该都会推出自己的 AI 框架。不是因为 Python 不好,Python 非常适合搓原型,一旦上线并且需要长期维护的时候,Python 的劣势就慢慢出现了。
Eino 目前还有一些小缺点,根据我这段时间的使用经历来看,可以简单列一下:
- 有一定的上手难度,并不像官方文档讲的那样曲线平滑。
- 文档里的项目案例比较单一,网上的教学视频几乎没有。
- 社区目前比较冷清,社区网站的用户体验比较糟糕。
3.2. 代码架构
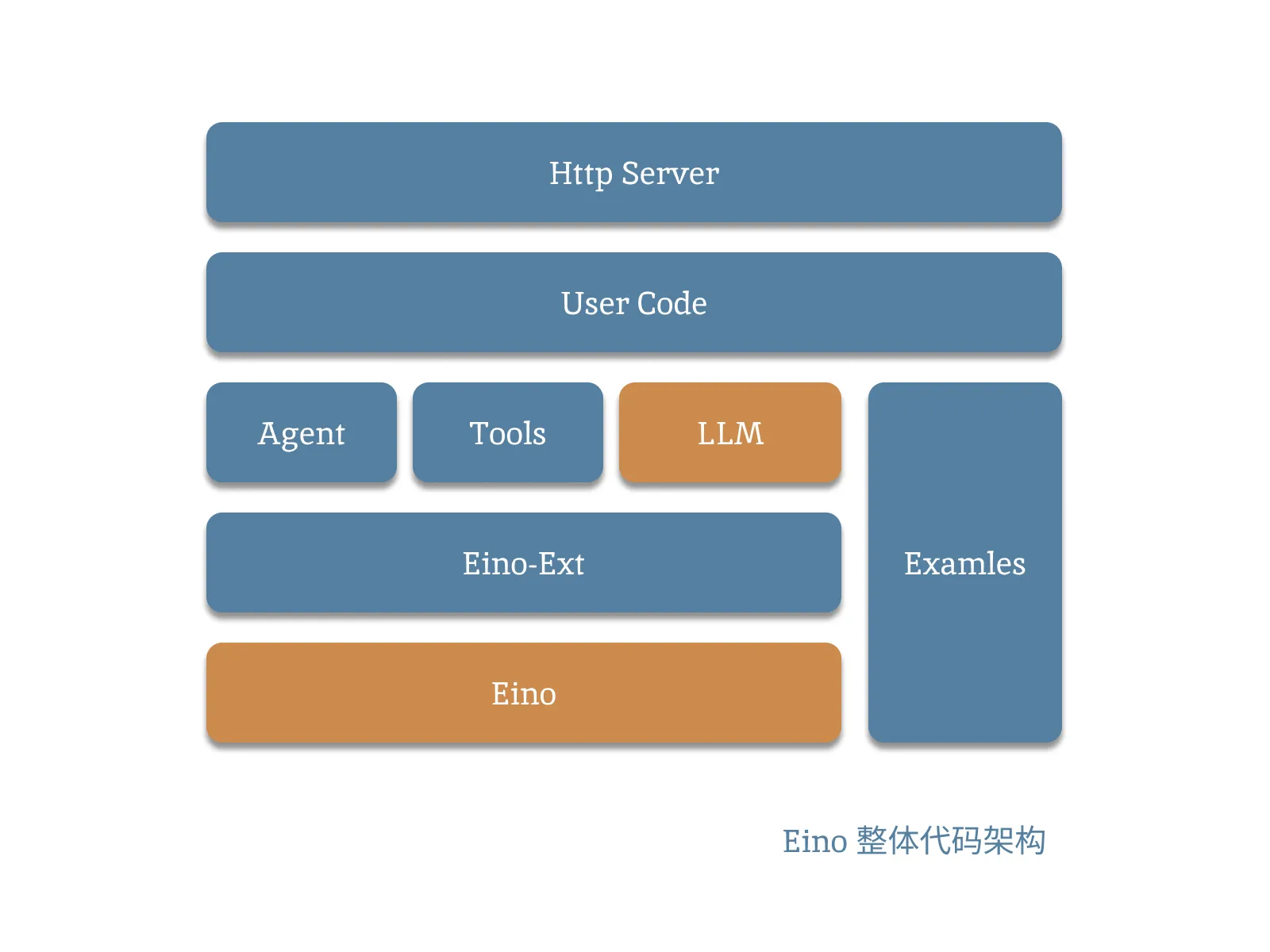
整个 Eino 的模块划分基本上按照这个结构,其中:
- Eino 主体只负责核心工作,比如编排、组件接口定义等等功能。
- Eino-Ext 可以认为是对接口的实现。市面上常见的模型,方法都已经做好了封装,基本上实现了开箱即用。缺点是,需要用哪一块需要手动去 Go Get。
- Agent、LLM 等就是 EXT 具体实现的组件,UserCode 调用这些组件完成具体的功能。
- Examles 里面有大量的具体实现。很多官方文档没有的内容,也可以在这里找到具体使用的例子。比如 使用 redis 来作为向量数据库。
- HttpServer 该框架没有提供任何 Web API 的能力。如果想要封装成 RPC 或者 Web 服务需要自行搭建。官方案例的早期版本里有使用 Hertz+Eino 实现 Chat 小服务的 Demo,感兴趣可以看下。
提示
如果之前也看过字节团队的开源项目的话,应该很容易理解 EXT 这个模块的作用,这个设计确实非常灵性,是一种软件架构的经典案例了。如果,公司业务复杂,代码又多又乱,那我建议你可以使用这种方法。
3.3. 技术上的优势
Eino 的优势那可太多了,光是最先开源的 Go 开发的 Ai 框架就已经很了不起了,作为第一个吃螃蟹的人,应该多多鼓励,希望它越来越好。我在粗略看完 Eino 的源码后,结合官方文档的描述,认为它最大的特点是内核稳定,其他的优势基本上都是这个特点延申出来的。
3.3.1. 内核稳定
我认为这是最近几年学习源码最大的收获,做人做事,都需要一个强大又稳定的内核。
这一块,我们直接看一下官方的原文描述:
我们认为,存在一个常见的组件列表,共同构成了大模型应用的常见组成部分。每类组件作为一个 interface,有完善、稳定的定义:具体的输入输出类型,明确的运行时 option,以及明确的流处理范式。
在明确的组件定义基础之上,我们认为,大模型应用开发存在通用的基座性质的能力,包括但不限于:处理模型输出的流式编程能力;支持横切面功能以及透出组件内部状态的 Callback 能力;组件具体实现超出组件 interface 定义范围的 option 扩展能力。
在组件定义和通用基座能力的基础上,我们认为,大模型应用开发存在相对固定的数据流转和流程编排范式:以 ChatModel(大模型)为核心,通过 ChatTemplate 注入用户输入和系统 prompt,通过 Retriever、Document Loader & Transformer 等注入上下文,经过 ChatModel 生成,输出 Tool Call 并执行,或输出最终结果。基于此,Eino 提供了上述组件的不同编排范式:Chain,链式有向无环图;Graph,有向图或有向无环图;Workflow,有字段映射能力的有向无环图。
对于初学者可能看的不太明白,谈谈我的理解:
首先,内核稳定的前提是对业务流程深刻的认识和理解。官方举了很多小例子来描述这一点,这也是我对字节开源团队非常赞赏的一点,他们的思路来源与实际开发任务,又略高于业务。说句实话,上文引用的内容,没有丰富一线开发经验,是编不出来的。透过这些,甚至能看到字节内部的一些业务场景的冰山一角,真的是不拿兄弟们当外人啊。
其次,在具体实现上,要选择合适的方式来保证内核稳定。Eino 使用的十字结构来拆分业务模块,从垂直角度来看,LLM 应用存在明显的开始和结束节点。从水平角度来看,LLM 应用又有着固定的数据流向和编排范式。使用 AOP 的思想把水平方向的模块拆分,提前做好 Callback 函数和 State 状态控制。将常见模块拆分,便于快速组装和搭建。
最后,只分享自己再业务中使用的场景和案例,并不强制某个模块只做固定功能。除了核心编排,将其他组件的使用让开发自由发挥。这种一点点的自由度,就足够玩出花样了。
3.3.2. 易扩展、高可靠、可观测
这一块,我们就不展开了。简单说下:
- 接口定义 + 扩展实现。后续有新的、更流行的模型、存储出现,可以快速接入,不需要更新核心。
- 大量使用泛型。开发只需要关注自己的结构体就好,降低代码理解,提高稳定性(相对 Python)
- 在编排中预留了 Callback 和其他一些功能,可以在任意节点中读取当前的状态和内容变化。这一点,在测试、线上问题排查的时候作用非常大。
3.3.3. 可视化编排工具
Eino 居然提供了可视化插件,这个确实很贴心了,vscode 和 Goland 都有。
相关信息
我也在学着用,还不太习惯。
4. 代码分块
4.1. 核心模块
4.1.1. Components
组件基本上是一下绝大多数模块的总称,也就是说下面的扩展组件里的模块也属于组件。我们在这一 Part,就只聊一下核心组件之一的 ChatModel 和 Prompt。
ChatModel:
常用的一般都是 ToolCallingChatModel。ToolCallingChatModel 可以实现类似链式调用的方式添加 tools 函数,在自带的 React Agent 里有用到。
(2025.08.04)在新版本中, ChatModel 目前正在逐渐废弃,后续统一用 ToolCallingChatModel 来代替。
type BaseChatModel interface {
Generate(ctx context.Context, input []*schema.Message, opts ...Option) (*schema.Message, error)
Stream(ctx context.Context, input []*schema.Message, opts ...Option) (
*schema.StreamReader[*schema.Message], error)
}
type ChatModel interface {
BaseChatModel
BindTools(tools []*schema.ToolInfo) error
}
type ToolCallingChatModel interface {
BaseChatModel
WithTools(tools []*schema.ToolInfo) (ToolCallingChatModel, error)
}Prompt:
type ChatTemplate interface {
Format(ctx context.Context, vs map[string]any, opts ...Option) ([]*schema.Message, error)
}4.1.2. Lambda
这个 Lambda 和 Runnable 算是整个编排的基础,Lambda 也是编排过程中的一个节点。我们后续会专门聊聊它是如何参与编排工作的。
type Lambda struct {
executor *composableRunnable
}
type composableRunnable struct {
i invoke
t transform
inputType reflect.Type
outputType reflect.Type
optionType reflect.Type
*genericHelper
isPassthrough bool
meta *executorMeta
// only available when in Graph node
// if composableRunnable not in Graph node, this field would be nil
nodeInfo *nodeInfo
}这四方式对应在知识地图里,大家可以看下。
type Runnable[I, O any] interface {
Invoke(ctx, I, ...CallOption) (O, error) // 标准调用
Stream(ctx, I, ...CallOption) (*StreamReader[O], error) // 流式输出
Collect(ctx, *StreamReader[I], ...CallOption) (O, error) // 流式输入
Transform(ctx, *StreamReader[I], ...CallOption) (*StreamReader[O], error) // 流式转换
}4.1.3. Compose
核心中的核心,基石中的基石。需要花时间认真阅读并学习的模块。就目前看下来,虽说提供了三种方式:Chain、Graph、WorkFlow。但本质上只有一种:Graph。
重要
Chain 是 Graph 的简化,WorkFlow 是 Graph 的高级封装。
我们这里就不添加代码了,另外这里需要了解两个常见的知识点:
相关信息
dag 和 pregel 的区别。
4.1.4. Callbacks
Callbacks 是我觉得做的最传统的一个模块,实现的功能让整个框架很优雅,但是实现的方式后续还可以持续优化。它的逻辑可以用一把手枪来 表述:
相关信息
BindCallback 是装填子弹,On 方法是扳机,Manger 是枪身,开发人员是枪手。
type RunInfo struct {
Name string
Type string
Component components.Component
}
type CallbackInput any
type CallbackOutput any
type Handler interface {
OnStart(ctx context.Context, info *RunInfo, input CallbackInput) context.Context
OnEnd(ctx context.Context, info *RunInfo, output CallbackOutput) context.Context
OnError(ctx context.Context, info *RunInfo, err error) context.Context
OnStartWithStreamInput(ctx context.Context, info *RunInfo,
input *schema.StreamReader[CallbackInput]) context.Context
OnEndWithStreamOutput(ctx context.Context, info *RunInfo,
output *schema.StreamReader[CallbackOutput]) context.Context
}
type CallbackTiming uint8
type TimingChecker interface {
Needed(ctx context.Context, info *RunInfo, timing CallbackTiming) bool
}另外,我们说的调试、可观测等等一系列功能都是基于 CallBack 的方式来实现的。
4.1.5. Other
这一块,我觉得没啥聊的,基本上就是定义了 TOOLS 工具,EXT 里有很多基于这个接口实现的功能,而且 MCP 也归属这一块。我觉得也就这一块值得聊一聊。
type BaseTool interface {
InvokeWithMap(ctx context.Context, args map[string]any, opts ...Option) (any, error)
GetToolInfo() *ToolInfo
}4.2. 扩展组件
4.2.1. Indexer
索引器,用来讲文档直接转为向量存储,需要配合 Embedding 使用,后续会展开聊一下。
type Indexer interface {
Store(ctx context.Context, docs []*schema.Document, opts ...Option) (ids []string, err error) // invoke
}4.2.2. Retriever
召回器,用来读取向量存储,需要配合 Embedding 使用,后续会展开聊一下。我目前已经在用的主要是 Redis 和 Milvus 两种。
type Retriever interface {
Retrieve(ctx context.Context, query string, opts ...Option) ([]*schema.Document, error)
}4.2.3. Embedding
词嵌入工具。本质上是 NLP 模型,调用方法和 LLM 模型本质上一摸一样。我自己已经尝试了多种方式,目前还是推荐使用 ollama+bge-m3 用来处理小型业务。
type Embedder interface {
EmbedStrings(ctx context.Context, texts []string, opts ...Option) ([][]float64, error) // invoke
}4.2.4. Document
文档组件可以分成三块:
Loader,从指定地方读取文件,目前支持本地和 URL。(基本上够用了)
Transformer,核心。用来给文档切片,提供市面上最常见的三种方式,希望后续能加上语义模式。
Parser,预处理文档。目前支持 PDF 和 HTML,够用,但不多。(未来肯定会增加的)
// Loader is a document loader.
type Loader interface {
Load(ctx context.Context, src Source, opts ...LoaderOption) ([]*schema.Document, error)
}
// Transformer is to convert documents, such as split or filter.
type Transformer interface {
Transform(ctx context.Context, src []*schema.Document, opts ...TransformerOption) ([]*schema.Document, error)
}
type Parser interface {
Parse(ctx context.Context, reader io.Reader, opts ...Option) ([]*schema.Document, error)
}4.3. 第三方组件
相关信息
目前 Eino 还没有非常明确的三方组件使用说明,我估计后续一定会更新的。
5. 关于 Flow
Flow 层提供了经过生产验证的预制解决方案,大幅降低开发成本,我目前在个人项目里简单用了下,能解决小不部分问题,但是需要消耗大量的 Token,适合快速出原型的场景。
通过学习和实践,目前的 Flow,基本上可以认为是对 LLM 的多层套娃,并且未来会越套越多。
5.1. ReAct Agent
关于这个知识点,可以看下这篇文章:https://react-lm.github.io/
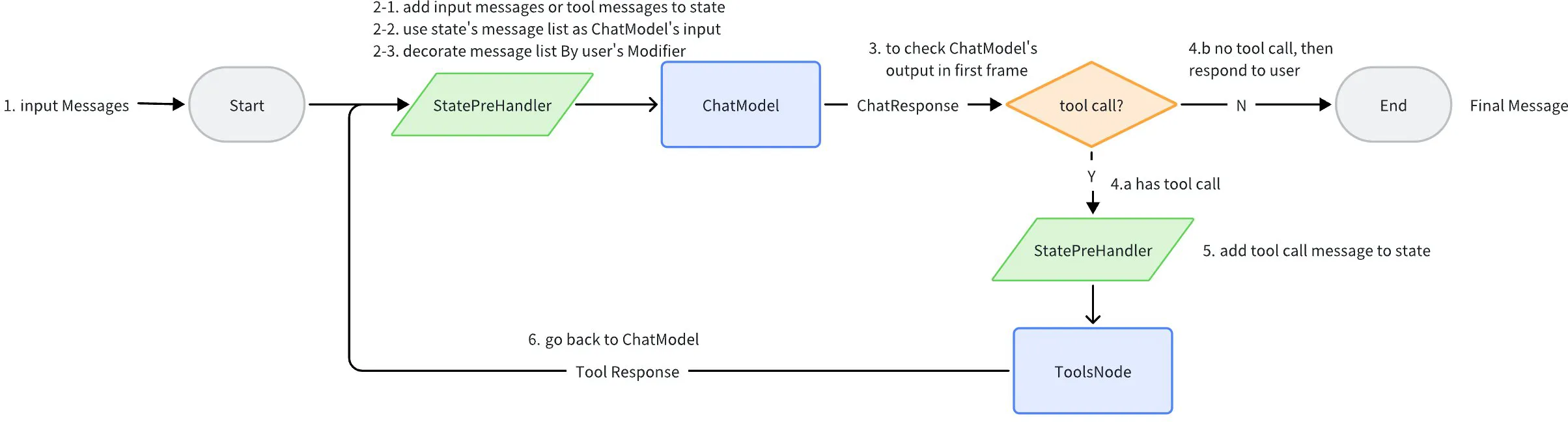
你可以简单的认为,React Agent 是预编排好的 LLM,它携带了一系列的 Tools。当运行的时候,大模型会根据情况找到合适的 Tool,然后将结果再次返回给大模型,然后循环,直到没有 Tool 需要调用以后,就可以返回结果了。
这个可以用一个案例很快跑通:deepseek + 高德地图的 MCP 服务,快速拉起一个旅游小助手。
5.2. Host Multi-Agent
Host Multi-Agent 是一个 Host 做意图识别后,跳转到某个专家 agent 做实际的生成。简单而言,就是本地(host)大模型,(当然这个 host 相对的,别理解错),在识别的用户意图后,会找到合适的 Agent 来帮你处理问题。
6. 个人理解
Eino 本身有非常明确的技术传承,我自己认为这个传承有两方面的理解。第一,组件划分和编排有非常明确的 Python 框架的模式,另外也有很多字节内部业务实践的一些经验。第二,代码的结构、实现和后续扩展都有字节开源项目鲜明的特征。这是非常好的习惯,希望后续能够一直保持。
目前 Agent 尚且处于一种比较朦胧的阶段,框架本身其实就是对现有业务线和技术线的封装,肯定不是最终形态。未来,框架在安全、部署、可观测、三方组件等等模块上肯定会有更多的优化,希望能从字节团队的代码里,找到解决自己公司业务问题的好思路。
最后,我需要把官方文档的这一段放出来,大家看一下。

重要
希望我,还有我的同事、朋友们能够实事求是,知行合一。