
投票 V3 版本
1.优化用户注册的功能
增加扩展字段
- 增加一个UUID字段,varchar(50) 。
- 增加一个UUID的 唯一索引。
uuid 有什么特性。全局唯一性,唯一ID,用户ID
B站,uid 2 208259 3493125102241833
qq 10000 10001 10002 10003 10007
把主键ID 作为一个用户ID 放出去,合适么?
从产品和运维还有架构等多方面角度 思考一下这个问题。
使用UUID 生成用户ID
string -> 雪花算法。
https://github.com/google/uuid
https://github.com/satori/go.uuid
go get github.com/google/uuid
go get github.com/satori/go.uuidpackage tools
import (
"fmt"
"github.com/google/uuid"
)
func GetUUID() string {
id := uuid.New() //默认V4 版本
fmt.Printf("uuid:%s,version:%s", id.String(), id.Version().String())
return id.String()
}
# ac91b393-09d9-496a-9d35-086257fc5ae82. 将所有数据库操作改造为原生SQL语句
为什么要用原生SQL
- 便于服务上线后,出现慢查询的时候进行排查。
SQL 给你,
- 简单业务场景下,原生SQL语句可以减少一次SQL语句Build的过程。提高效率。
- 复查业务场景下,原生SQL语句可以提高准确性,避免build的过程中,出现隐形BUG,极低。
- 缺点就是需要多写一些代码。
建议,能用原生SQL语句的地方尽量自己编写SQL语句。两个原因:
- 对于业务的查询场景有一个清醒的认识。便于后续的优化,排查,建索引等。
- 提高自己SQL的能力。简单的SQL场景不去练习,是不可能写出来复查场景的SQL的。
这些都是经历一个个BUG,迭代一个个业务场景后的感受。
什么是SQL注入
SQL 注入是一种常见的安全漏洞,它发生在应用程序未正确验证、转义或过滤用户提供的输入数据,并将其直接拼接到 SQL 查询语句中的情况下。攻击者可以利用这个漏洞注入恶意的 SQL 代码,从而执行未经授权的数据库操作。
原理可以百度,GPT。
select * from user where name = ? limit 1
# 1 OR 1=1
select * from user where name = '1 OR 1=1' limit 1GORM有什么用
我们把这个问题摆的很靠后,希望你先学会用这个东西,再来拐回头来聊这个组件。变相的帮你做了一次预习。
Gorm 是工作中天天用,但是面试的时候 不怎么问的组件。
- GORM 究竟是个什么东西。XORM的 GO RM G -ORM 什么叫ORM
- GORM提供了哪些功能。
a.链式操作 b.做了参数的转译,变相的降低了SQL注入的风险。c.它帮我们维持了MySQL的链接池。
- GORM有什么优势,又有什么问题。
- 提高了我们对数据库操作的便捷性。
- 问题:降低了我们写SQL的能力。
3. 将所有接口改造为RestFul接口
什么是RestFul接口?
这里可以参考 阮一峰的博客。https://ruanyifeng.com/blog/2014/05/restful_api.html
蚂蚁金服的前端团队,是国内独一档的存在。目前,没有之一。
本质上,把一切请求当作对一种资源的操作。有哪些操作:增删改查,也就是CURD。
动词含义
常用:
- GET(SELECT):从服务器取出资源(一项或多项)。
- POST(CREATE):在服务器新建一个资源。
- PUT(UPDATE):在服务器更新资源(客户端提供改变后的完整资源)。
- PATCH(UPDATE):在服务器更新资源(客户端提供改变的属性)。
- DELETE(DELETE):从服务器删除资源。
不常用:
- HEAD:获取资源的元数据。
- OPTIONS:获取信息,关于资源的哪些属性是客户端可以改变的。
使用APIFOX测试。
返回码含义
可以再复习一下。
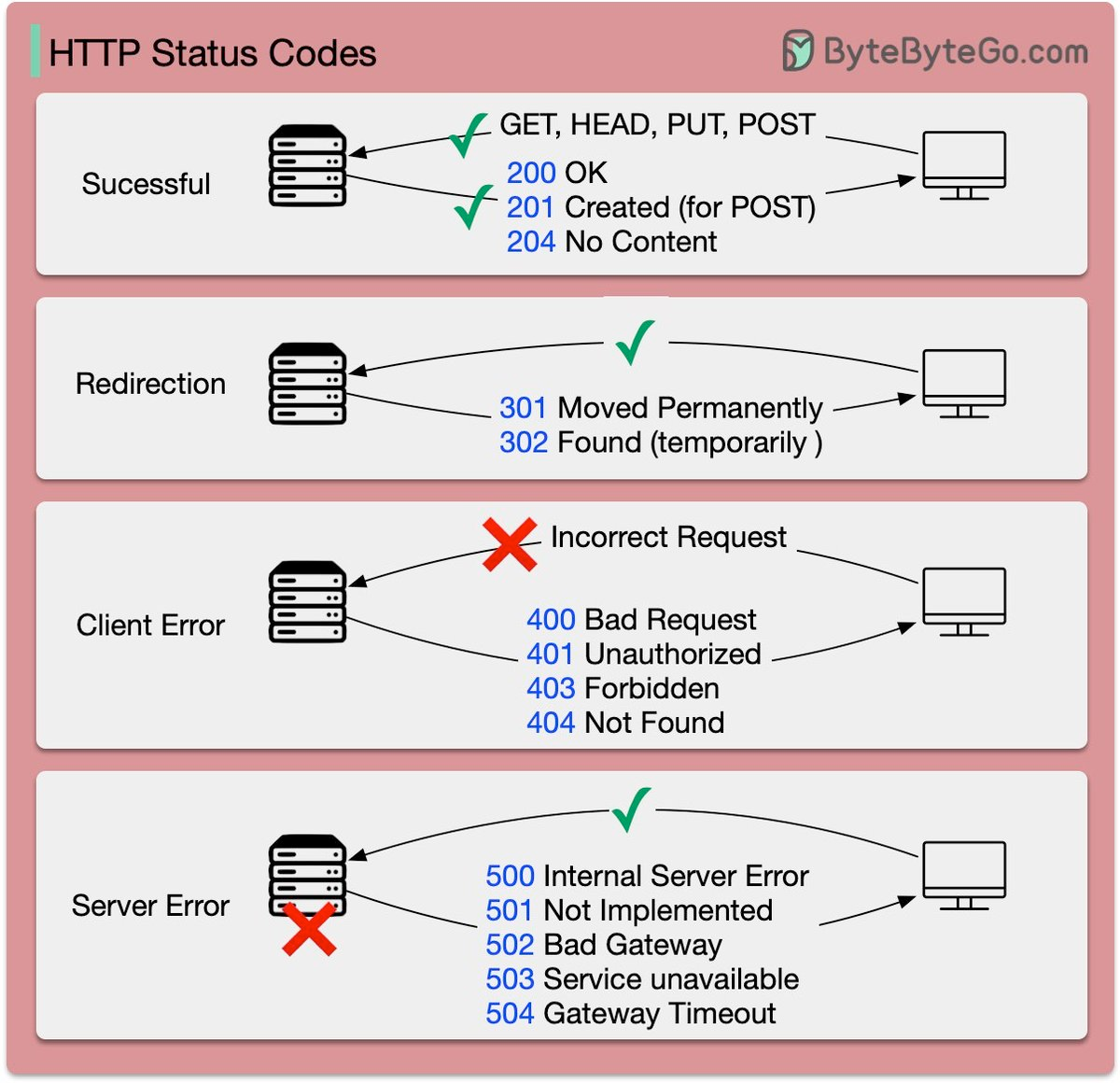
- 200 OK - [GET]:服务器成功返回用户请求的数据,该操作是幂等的(Idempotent)。
- 201 CREATED - [POST/PUT/PATCH]:用户新建或修改数据成功。
- 202 Accepted - [*]:表示一个请求已经进入后台排队(异步任务)
- 204 NO CONTENT - [DELETE]:用户删除数据成功。
- 400 INVALID REQUEST - [POST/PUT/PATCH]:用户发出的请求有错误,服务器没有进行新建或修改数据的操作,该操作是幂等的。
- 401 Unauthorized - [*]:表示用户没有权限(令牌、用户名、密码错误)。
- 403 Forbidden - [*] 表示用户得到授权(与401错误相对),但是访问是被禁止的。
- 404 NOT FOUND - [*]:用户发出的请求针对的是不存在的记录,服务器没有进行操作,该操作是幂等的。
- 406 Not Acceptable - [GET]:用户请求的格式不可得(比如用户请求JSON格式,但是只有XML格式)。
- 410 Gone -[GET]:用户请求的资源被永久删除,且不会再得到的。
- 422 Unprocesable entity - [POST/PUT/PATCH] 当创建一个对象时,发生一个验证错误。
- 500 INTERNAL SERVER ERROR - [*]:服务器发生错误,用户将无法判断发出的请求是否成功。
还有没有其他通信方式
有,还很多。
- SOAP 早就没人用了。
- REST 诞生的很早,目前还在用。http协议
- GraphQL 用得不多,主要是数据场景里用的很多。
- RPC 最近火起来的,以后用的最多的通讯方式。基本上是微服务的基础。
- WebSocket 一般是即时通讯或者网页游戏要使用。实现一个简单的聊天室
参考:https://blog.bytebytego.com/p/soap-vs-rest-vs-graphql-vs-rpc

RestFul接口中的幂等性是什么
简而言之,多次操作,结果相同。
比如:
GET 操作,自带幂等性。
其他操作,需要进行一些限制才能实现幂等性。
最简单实现幂等性的 是删除接口 ,
其次 更新接口
i.把title 更新成 香香编程喵喵喵 id =5
ii.把 count 更新成 count++ id = 5
最后,新增接口
1. 写入之前查一下。简单
2. 给title 字段,在数据库中 增加一个唯一索引。 简单
3. 有一些特殊场景需要用的。先生成一个UUID给前端,前端提交的时候 再把UUID 传过来 。
问题:新增接口如何实现幂等性?修改接口如何实现幂等性?
4. 使swagger生成接口文档
安装SWAG
首先,安装 swag:https://github.com/swaggo/swag
go install github.com/swaggo/swag/cmd/swag@latest安装Gin组件
接着,我们是基于Gin 框架搭建的,需要装一个Gin的中间件:
https://github.com/swaggo/gin-swagger
go get -u github.com/swaggo/gin-swagger
go get -u github.com/swaggo/files
go get -u github.com/swaggo/swag补充注释
再接着,在DoLogin前面补充下Swagger的注释:
// @contact.name Vote API
// @contact.email 香香编程喵喵喵
// @license.name Apache 2.0
// @license.url http://www.apache.org/licenses/LICENSE-2.0.html
//以上注释在main函数之前
// DoLogin godoc
// @Summary 执行用户登录
// @Description 执行用户登录
// @Tags login
// @Accept json
// @Produce json
// @Param name body User true "login User"
// @Success 200 {object} tools.ECode
// @Router /login [post]生成文档
然后执行下面的命令
swag init最后登录:
http://127.0.0.1:8080/swagger/index.html#/
为什么写接口文档
- 公司开发项目,讲究一个 接口先行。 人月神话。基于接口文档 mock 数据。
- 程序员有个坏毛病,不喜欢写文档。代码和文档 一样重要。顺手 写个文档。每次迭代的时候,写一个优化文档。像流水账一样。
多写文档,多写技术方案,多学习别人的技术方案。
5. 引入Redis缓存
https://redis.uptrace.dev/zh/guide/
数据缓存有什么用?
计算机组成原理,操作系统
一句话总结:加快数据读取,提高服务的响应效率。
我们从数据库里,存在磁盘里,读数据,效率不太行。
如果我们从缓存里,读数据,效率会高很多。
缓存怎么用?
go get -u github.com/redis/go-redis/v9
# 安装对应的模块在model 中新增一个Redis 模块
func NewRdb() {
rdb := redis.NewClient(&redis.Options{
Addr: "127.0.0.1:6379",
Password: "", // no password set
DB: 0, // use default DB
})
Rdb = rdb
return
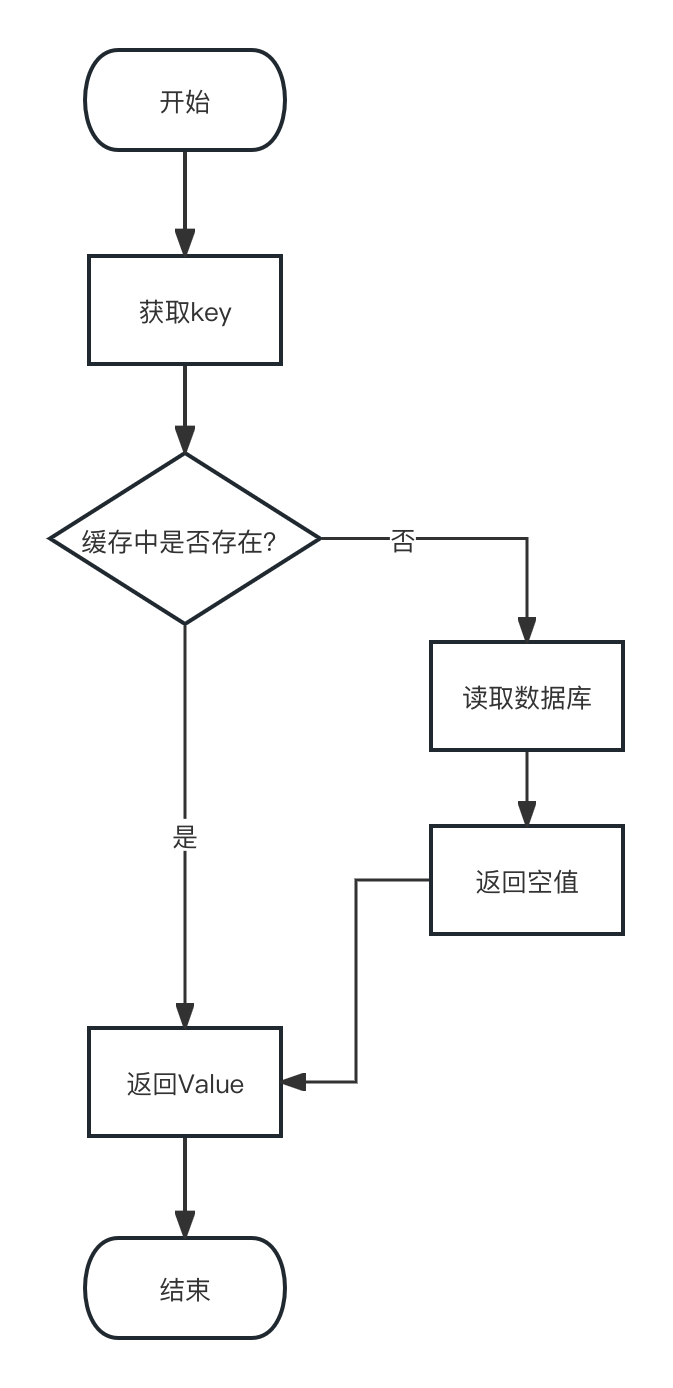
}按照下面的流程图,写一个使用缓存的接口
package model
import (
"context"
"encoding/json"
"fmt"
"time"
)
func GetVoteCache(c context.Context, id int64) VoteWithOpt {
var ret VoteWithOpt
key := fmt.Sprintf("key_%d", id)
fmt.Printf("key:%s\n", key)
voteStr, err := Rdb.Get(c, key).Result()
if err == nil || len(voteStr) > 0 {
//存在数据
_ = json.Unmarshal([]byte(voteStr), &ret)
return ret
}
fmt.Printf("err:%s\n", err.Error())
vote := GetVote(id)
if vote.Vote.Id > 0 {
//写入缓存
s, _ := json.Marshal(vote)
err1 := Rdb.Set(c, key, s, 3600*time.Second).Err()
if err1 != nil {
fmt.Printf("err1:%s\n", err1.Error())
}
ret = vote
}
return ret
}缓存在使用中有哪些问题?
我们可以把问题大致分为这四类,我们做业务开发一般只关注前三类
- 数据一致性问题。高频问题 读时更新,写时删除。
- 击穿、穿透和雪崩的问题。
- 不同业务场景下选择合适的缓存类型问题。string set list hash zset
- 分布式和集群下,缓存稳定性和可用性的问题。运维与架构师需要特别关注。