
9 缓存击穿问题
1. 什么是缓存击穿
1.1. 介绍
缓存击穿是指某个数据暂时不在缓存里,需要回源到数据库读取,结果同一时间出现了大量的请求压在了 DB 上,进而导致数据库异常拖垮整个服务。
如果你还有印象,我们在讲”读更新、写删除“的时候,就明确说过,这个方法好用,但是存在击穿问题。
1.2. 为什么危害巨大
参考下图:
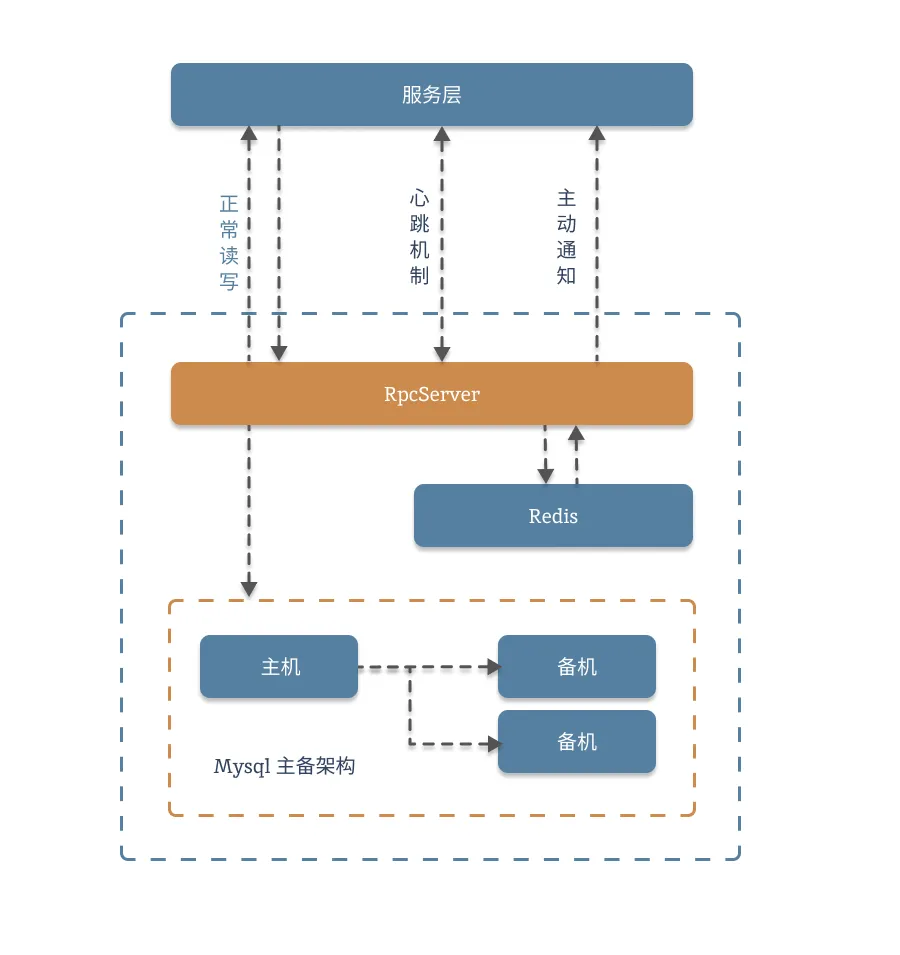
我们使用缓存的目的有两个,一是加快请求响应,提高性能。二是保护我们的数据库,防止大流量压垮服务。如果出现击穿,则两个目的都无法达到。
警告
系统架构就像积木,越靠下的模块越需要稳定。数据库往往都在系统架构的最底层,如果出现问题很有可能拖垮整个服务。
2. 解决方案
2.1. 复现场景
首先,找到我们之前的”读更新、写删除“的代码:
package logic
import (
"context"
"errors"
"fmt"
"github.com/redis/go-redis/v9"
"net/http"
"strconv"
"time"
"training/cache/appv0/db"
)
func GetBook(w http.ResponseWriter, r *http.Request) {
if r.Method != http.MethodGet {
http.Error(w, "只支持 GET 请求", http.StatusMethodNotAllowed)
return
}
id := r.URL.Query().Get("id")
//先获取redis
key := fmt.Sprintf("book_%s", id)
cache, err := db.Rdb.Get(context.Background(), key).Result()
if err != nil && !errors.Is(err, redis.Nil) {
_, _ = fmt.Fprintf(w, "缓存获取失败:"+fmt.Sprint(cache))
return
}
//缓存的Key 不存在,走回溯逻辑
if errors.Is(err, redis.Nil) {
//redis 不存在就查询数据库
info := db.Info{}
data := info.Get(1)
//无论数据存在不存在 都将数据缓存
cache = fmt.Sprint(data)
_ = db.Rdb.Set(context.Background(), key, cache, time.Second*5).Err()
}
// 向客户端发送响应
_, _ = fmt.Fprintf(w, "这是查数据库的结果:"+cache)
}
func SetBook(w http.ResponseWriter, r *http.Request) {
if r.Method != http.MethodGet {
http.Error(w, "只支持 Get 请求", http.StatusMethodNotAllowed)
return
}
name := r.URL.Query().Get("name")
id := r.URL.Query().Get("id")
//先写数据库,然后删除掉缓存。
info := db.Info{}
idInt, _ := strconv.Atoi(id)
if err := info.Save(idInt, name); err != nil {
_, _ = fmt.Fprintf(w, "数据库更新失败!")
return
}
//这里不再更新缓存,而是直接删除数据。
key := fmt.Sprintf("book_%s", id)
_ = db.Rdb.Del(context.TODO(), key).Err()
_, _ = fmt.Fprintf(w, "数据更新完成,缓存已经清除!")
}相关信息
引申:缓存不存在然后回源获取数据,在业务上属于是正常操作,这一点是不存在问题的。问题在于,如果刚好回源的这个数据,同时有成百上千的请求,岂不是要出大事?(这就是 Hot Key 问题)
2.2. 异步更新
2.3. 基于 Binlog
2.4. 基于租约
除了上面这几种方式以外,还有更多 更合适的方案:
3. 使用锁
绝大多数同学下意识能想到的方案就是加锁,这符合正常人的思路。我们先用加锁的方式来搞定这个问题。
重要
加锁确实能搞定这个问题,但我们一般不会使用。
3.1. 使用互斥锁
看下代码,
func GetBookV1(w http.ResponseWriter, r *http.Request) {
if r.Method != http.MethodGet {
http.Error(w, "只支持 GET 请求", http.StatusMethodNotAllowed)
return
}
id := r.URL.Query().Get("id")
//先获取redis
key := fmt.Sprintf("book_%s", id)
cache, err := db.Rdb.Get(context.Background(), key).Result()
if err != nil && !errors.Is(err, redis.Nil) {
_, _ = fmt.Fprintf(w, "缓存获取失败:"+fmt.Sprint(cache))
return
}
//缓存的Key 不存在,走回溯逻辑
if errors.Is(err, redis.Nil) {
//redis 不存在就查询数据库
var mu sync.Mutex
mu.Lock()
defer mu.Unlock()
info := db.Info{}
data := info.Get(1)
//无论数据存在不存在 都将数据缓存
cache = fmt.Sprint(data)
_ = db.Rdb.Set(context.Background(), key, cache, time.Second*5).Err()
}
// 向客户端发送响应
_, _ = fmt.Fprintf(w, "这是查数据库的结果:"+cache)
}就这么简单?对,就这么简单,但我们一般不用。
使用互斥锁,确实可以解决这类问题。但是代价是巨大的,有个问题会严重拖累服务:
第一个是等待加锁导致的服务超时。假如,现在有锁竞争,你这边需要等待 1 秒的时间,可是服务要求你 500ms 内必须要返回数据,所以你不得不返回一个 500,服务内部错误,或者 504 time-out 超时。这显然不行。
第二个是互斥锁的粒度仅限于本机服务。如果我是一个大的集群服务,同时有 50 台机器,岂不是同时还是有 50 个请求会走到数据库上。如果同时又 100 个 Key,出现击穿,那么 DB岂不是要抗 5000QPS 了?这个风险还是有点高。
3.2. 使用 NX 锁
使用 Redis Nx 锁,可以解决本机互斥锁的部分问题:将本机锁,变成全局锁,这样子无论集群有多少太机器,对于一个 Key 同一时间也就只有一个请求会打到 DB 上。看下代码:
func GetBookV2(w http.ResponseWriter, r *http.Request) {
if r.Method != http.MethodGet {
http.Error(w, "只支持 GET 请求", http.StatusMethodNotAllowed)
return
}
id := r.URL.Query().Get("id")
//先获取redis
key := fmt.Sprintf("book_%s", id)
cache, err := db.Rdb.Get(context.Background(), key).Result()
if err != nil && !errors.Is(err, redis.Nil) {
_, _ = fmt.Fprintf(w, "缓存获取失败:"+fmt.Sprint(cache))
return
}
//缓存的Key 不存在,走回溯逻辑
if errors.Is(err, redis.Nil) {
//redis 不存在就查询数据库
//加NX锁
lockKey := fmt.Sprintf("book_lock_%s", id)
flag := nxLock(lockKey)
defer nxUnlock(lockKey)
if !flag {
_, _ = fmt.Fprintf(w, "加锁失败:"+fmt.Sprint(cache))
return
}
info := db.Info{}
data := info.Get(1)
//无论数据存在不存在 都将数据缓存
cache = fmt.Sprint(data)
_ = db.Rdb.Set(context.Background(), key, cache, time.Second*5).Err()
nxUnlock(lockKey)
}
// 向客户端发送响应
_, _ = fmt.Fprintf(w, "这是查数据库的结果:"+cache)
}
var lockValue string
func nxLock(key string) bool {
//生成锁的值
lockValue = fmt.Sprintf("lock-%d-%d", time.Now().Unix(), rand.Intn(math.MaxInt32))
lockKey := fmt.Sprintf("book_lock_%s", key)
err := retry.Do(func() error {
if _, err := db.Rdb.SetNX(context.Background(), lockKey, lockValue, time.Second*3).Result(); err != nil {
return err
}
return nil
}, retry.Attempts(3))
if err != nil {
return false
}
return true
}
func nxUnlock(key string) {
script := `
if redis.call("GET", KEYS[1]) == ARGV[1] then
return redis.call("DEL", KEYS[1])
else
return 0
end
`
_, err := db.Rdb.Eval(context.Background(), script, []string{key}, lockValue).Result()
if err != nil {
fmt.Printf("释放锁失败: %v\n", err)
return
}
}使用 NX 锁,其实也就是解决了第二个问题的一部分,并没有从根本上解决加锁带来的性能降低和其他隐患,而且 NX 锁还引出了一些新的问题:
- 解锁的时候,不能够解别人的锁。
- 锁的时间,不好把握。
3.3. 使用分布式锁
使用分布式锁,只能解决 NX 锁存在的问题,并不能够解决锁这个方案本身存在的问题,因此我们在这里只做了解即可。
4. 多级缓存
这是一个万金油方案,也是最常用的方案,用这个方案一般不会有大的 问题,只是可能造成小范围的数据不一致。
4.1. 什么是多级缓存
我们来看下 Ai 给你生成的答案:
多级缓存是一种通过在不同层级或位置部署缓存组件,以提升系统数据读取效率、降低后端压力的架构设计模式。它通过将热点数据按访问频率、时效性等维度分层存储,实现 “就近获取数据” 的目标,常用于高并发、大数据量的场景。
相关信息
是不是每个字你都能看懂,连在一块就看不太明白了。
我们再来看一个视频:
“楚帮场,孔过瘾,丁炸桥,总懵逼,陈十年!”_哔哩哔哩_bilibili
提示
楚帮场和孔过瘾的方案,基本上就是多级缓存的思路。丁炸桥厉害点,是多级缓存+NX 锁/单飞的思路。
这样,是不是方便你理解一些了?总结下来多级缓存就是一个思路:
重要
合理分配资源,依托有利地形,层层阻击。
4.2. 实现方案
我们来画个图,数一数,现在手上有的资源:
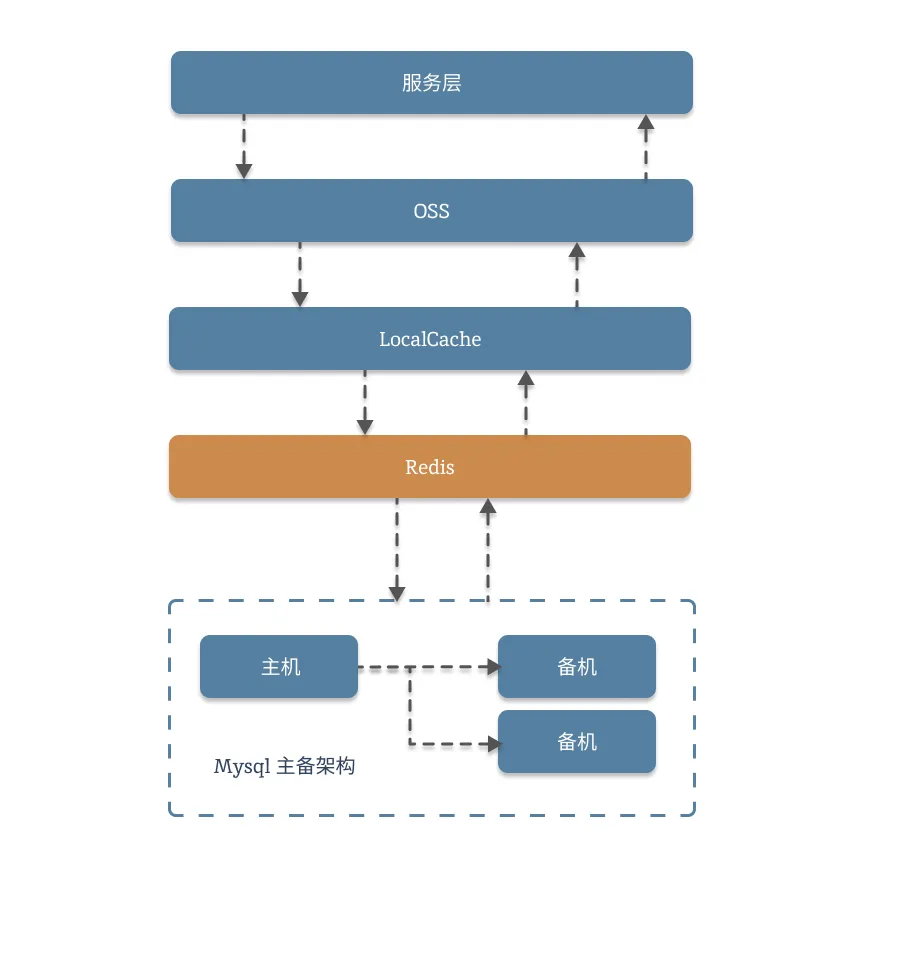
这是最复杂的实现方案,也是最常用的方案,希望大家能认真实现。
4.3. OSS
关于什么是 OSS 大家可以看下阿里云的简介和使用案例哈,这里就不再多讲了
相关信息
引申:什么是 OSS?(一道经典面试题)
4.3.1. 实现校验和上传
先实现 代码:
package tools
import (
"bytes"
"fmt"
"github.com/aliyun/aliyun-oss-go-sdk/oss"
)
func newOssClient() *oss.Client {
// 创建OSSClient实例
client, err := oss.New(
"Endpoint", // 如:oss-cn-hangzhou.aliyuncs.com
"AccessKeyID", // 访问密钥ID
"AccessKeySecret", // 访问密钥Secret
oss.Timeout(30, 60), // 连接超时30秒,读写超时60秒(可选)
)
if err != nil {
fmt.Println("newOssClient Error:", err)
return nil
}
return client
}
func OssExist(url string) bool {
client := newOssClient()
if client == nil {
return false
}
bucket, err := client.Bucket("test")
if err != nil {
fmt.Println("OssExist Error:", err.Error())
return false
}
exist, err := bucket.IsObjectExist(url)
if err != nil {
fmt.Println("OssExist Error:", err.Error())
return false
}
return exist
}
func SetDataToOss(url string, data []byte) bool {
client := newOssClient()
if client == nil {
return false
}
bucket, err := client.Bucket("test")
if err != nil {
fmt.Println("SetDataToOss Error:", err.Error())
return false
}
// 上传二进制数据
err = bucket.PutObject("object-key", bytes.NewReader(data))
if err != nil {
fmt.Println("Error:", err)
return false
}
return true
}4.3.2. 在接口中使用
一般有两个用法:
第一种,由服务端在接口中通过返回 302 来使用:
//先获取OSS
filename := fmt.Sprintf("book_oss_%s", id)
if tools.OssExist(filename) {
//如果OSS存在,就直接返回OSS地址,让它自己跳转
url := fmt.Sprintf("http://oss-cn-hangzhou.aliyuncs.com/%s/%s", "你的bucket", filename)
w.WriteHeader(http.StatusFound) //这里一定返回302 ,让客户端自己跳转
_, _ = w.Write([]byte(url))
return
}第二种,有前端自行判断。使用拦截器,先访问 OSS,如不存在,再访问接口。
一般情况下,都会选择第二种,由前端或者网管层来处理。当前端、或者网关服务功能不健全,或者开发压力较大的时候,会用第一种方法临时凑合下。
4.3.3. 异步更新 OSS
通常情况下,OSS 只会缓存固定的一些可以预测到的热门数据,因此会选用异步更新的方式。
package schedule
import (
"encoding/json"
"fmt"
"time"
"training/cache/appv8/db"
"training/cache/appv8/tools"
)
func Run() {
ticker := time.NewTicker(10 * time.Minute) // 一般情况下,OSS的更新时间都是分钟级的,因为OSS 往往需要做CDN加速,普遍的生效时间都在10分钟以内
for _ = range ticker.C {
setOss()
}
}
func setOss() {
id := 1
filename := fmt.Sprintf("book_oss_%d", id)
info := db.Info{}
data := info.Get(id)
if data != nil {
s, _ := json.Marshal(data)
tools.SetDataToOss(filename, s)
}
return
}4.4. 本地缓存
本地缓存这个也很好理解,这一块的技术选型有很多,我们挑两个来带大家了解下。
4.4.1. 基于 Map 的本地缓存
代码实现:
package tools
import "sync"
var Cache cache
func NewCache() {
Cache = cache{}
}
type cache struct {
data map[string]interface{}
mux sync.RWMutex
}
func (c *cache) Set(k string, v interface{}) {
c.mux.Lock()
defer c.mux.Unlock()
c.data[k] = v
return
}
func (c *cache) Get(k string) (interface{}, bool) {
c.mux.RLock()
defer c.mux.RUnlock()
data, ok := c.data[k]
return data, ok
}因为,Map 它是并发不安全的,因此我们用了一个加锁的方式。然后,我们只需要在业务代码中添加:
func GetBookV4(w http.ResponseWriter, r *http.Request) {
if r.Method != http.MethodGet {
http.Error(w, "只支持 GET 请求", http.StatusMethodNotAllowed)
return
}
id := r.URL.Query().Get("id")
//先获取OSS
filename := fmt.Sprintf("book_oss_%s", id)
if tools.OssExist(filename) {
//如果OSS存在,就直接返回OSS地址,让它自己跳转
url := fmt.Sprintf("http://oss-cn-hangzhou.aliyuncs.com/%s/%s", "你的bucket", filename)
w.WriteHeader(http.StatusFound) //这里一定返回302 ,让客户端自己跳转
_, _ = w.Write([]byte(url))
return
}
//如果OSS不存在,从本地缓存中读取一个值
key := fmt.Sprintf("book_%s", id)
local, ok := tools.Cache.Get(key)
if ok {
_, _ = fmt.Fprintf(w, "这是查数据库的结果:"+fmt.Sprint(local))
return
}
//如果本地缓存中并不存在,那么再进行回溯
//先获取redis
cache, err := db.Rdb.Get(context.Background(), key).Result()
if err != nil && !errors.Is(err, redis.Nil) {
_, _ = fmt.Fprintf(w, "缓存获取失败:"+fmt.Sprint(cache))
return
}
//缓存的Key 不存在,走回溯逻辑
if errors.Is(err, redis.Nil) {
//redis 不存在就查询数据库
//加NX锁
info := db.Info{}
data := info.Get(1)
if data.ID > 0 {
go func() {
tools.Cache.Set(key, data)
}()
}
//无论数据存在不存在 都将数据缓存
cache = fmt.Sprint(data)
_ = db.Rdb.Set(context.Background(), key, cache, time.Second*5).Err()
}
// 向客户端发送响应
_, _ = fmt.Fprintf(w, "这是查数据库的结果:"+cache)
}这样子,就是一个标准的带有多级缓存机制的业务逻辑了,通过这种方式可以有效防止 击穿 现象的发生。
但是,我们自己实现的这个本地缓存,有几个问题不好处理:
- 没有缓存淘汰机制,服务运行时间太久,塞的数据太多,会出现内存泄露。
- 基于 Map 实现。Map 存在的那些问题,也无法避免。
- 没办法自动实现缓存内容的过期。
4.4.2. 基于 GCache 的本地缓存
Go 实现的本地缓存库特别的多,能数上号的:go-cache,bigcache,groupcache,还有一些框架比如 go-zero 里自带的 cache 等等。我们为什么选择 gcache,因为我用得多……B站得 krtaos 用的也是这个。
go get -u github.com/bluele/gcache它的用法很简单啊,非常简单,开箱即用,而且它还很号的解决了上面几个问题。关于它的源码学习,我们后续会专门写一个博文,简单介绍介绍。看下代码:
package tools
import "github.com/bluele/gcache"
var Gcache gcache.Cache
//tools.Gcache = gcache.New(100).LRU().Build()func GetBookV5(w http.ResponseWriter, r *http.Request) {
if r.Method != http.MethodGet {
http.Error(w, "只支持 GET 请求", http.StatusMethodNotAllowed)
return
}
id := r.URL.Query().Get("id")
//先获取OSS
filename := fmt.Sprintf("book_oss_%s", id)
if tools.OssExist(filename) {
//如果OSS存在,就直接返回OSS地址,让它自己跳转
url := fmt.Sprintf("http://oss-cn-hangzhou.aliyuncs.com/%s/%s", "你的bucket", filename)
w.WriteHeader(http.StatusFound) //这里一定返回302 ,让客户端自己跳转
_, _ = w.Write([]byte(url))
return
}
//如果OSS不存在,从本地缓存中读取一个值
key := fmt.Sprintf("book_%s", id)
local, _ := tools.Gcache.Get(key)
if local != "" {
_, _ = fmt.Fprintf(w, "这是查数据库的结果:"+fmt.Sprint(local))
return
}
//如果本地缓存中并不存在,那么再进行回溯
//先获取redis
cache, err := db.Rdb.Get(context.Background(), key).Result()
if err != nil && !errors.Is(err, redis.Nil) {
_, _ = fmt.Fprintf(w, "缓存获取失败:"+fmt.Sprint(cache))
return
}
//缓存的Key 不存在,走回溯逻辑
if errors.Is(err, redis.Nil) {
//redis 不存在就查询数据库
//加NX锁
info := db.Info{}
data := info.Get(1)
if data.ID > 0 {
go func() {
_ = tools.Gcache.Set(key, data)
}()
}
//无论数据存在不存在 都将数据缓存
cache = fmt.Sprint(data)
_ = db.Rdb.Set(context.Background(), key, cache, time.Second*5).Err()
}
// 向客户端发送响应
_, _ = fmt.Fprintf(w, "这是查数据库的结果:"+cache)
}5. 单飞 SingleFlight
这是单飞,你不要想歪了
5.1. 单飞的原理
在 Go 语言中,SingleFlight 是一种并发控制机制,用于合并相同请求,避免重复计算。它的核心思想是对于同一时间内的相同请求,只执行一次,然后将结果共享给所有等待的请求者。举个例子:
同时有协程 1,2,3 访问数据 A,此时为了并发安全,需要加一个锁,这样子整体就会退化成顺序执行,效率会降低。那么,我们起一个协程,让 1 访问 A,再将访问结果通过 channel 传递给,2 和 3 ,如此,就可以实现 123 同时访问,但实际上只有一个人访问成功,其他人拿到的是数据的副本。
5.2. 用法
SingleFlight 的用法超级简单:
var sf singleflight.Group
func GetBookV6(w http.ResponseWriter, r *http.Request) {
if r.Method != http.MethodGet {
http.Error(w, "只支持 GET 请求", http.StatusMethodNotAllowed)
return
}
id := r.URL.Query().Get("id")
//先获取OSS
filename := fmt.Sprintf("book_oss_%s", id)
if tools.OssExist(filename) {
//如果OSS存在,就直接返回OSS地址,让它自己跳转
url := fmt.Sprintf("http://oss-cn-hangzhou.aliyuncs.com/%s/%s", "你的bucket", filename)
w.WriteHeader(http.StatusFound) //这里一定返回302 ,让客户端自己跳转
_, _ = w.Write([]byte(url))
return
}
//如果OSS不存在,从本地缓存中读取一个值
key := fmt.Sprintf("book_%s", id)
local, _ := tools.Gcache.Get(key)
if local != "" {
_, _ = fmt.Fprintf(w, "这是查数据库的结果:"+fmt.Sprint(local))
return
}
//如果本地缓存中并不存在,那么再进行回溯
//先获取redis
cache, err := db.Rdb.Get(context.Background(), key).Result()
if err != nil && !errors.Is(err, redis.Nil) {
_, _ = fmt.Fprintf(w, "缓存获取失败:"+fmt.Sprint(cache))
return
}
//缓存的Key 不存在,走回溯逻辑
if errors.Is(err, redis.Nil) {
//redis 不存在就查询数据库
//加NX锁
sfKey := fmt.Sprintf("single_book_%s", id)
ret, err1, _ := sf.Do(sfKey, func() (interface{}, error) {
info := db.Info{}
data := info.Get(1)
if data.ID > 0 {
go func() {
_ = tools.Gcache.Set(key, data)
}()
}
//无论数据存在不存在 都将数据缓存
cache = fmt.Sprint(data)
_ = db.Rdb.Set(context.Background(), key, cache, time.Second*5).Err()
return data, nil
})
if err1 != nil {
_, _ = fmt.Fprintf(w, "sf失败,缓存获取失败:"+fmt.Sprint(cache))
return
}
// 向客户端发送响应
_, _ = fmt.Fprintf(w, "这是查数据库的结果:"+fmt.Sprint(ret))
}
}5.3. 优缺点
优点的话,非常明显:可以显著降低并发请求,有效缓解击穿或者穿透的问题。而且它非常的灵活,你可以根据具体的情况选择将单飞加在 DB 层或者 Cache 层,从而保护需要抗流量的组件。(典型的加一层思想)
缺点的话,容易出现请求超时,或者 其他原因导致失败的现象。所以,我们一般会配合 retry 以及超时一起使用:
// 单飞+重拾
retry.Do(func() error {
sfKey := fmt.Sprintf("single_book_%s", id)
ret, err, _ = sf.Do(sfKey, func() (interface{}, error) {
info := db.Info{}
data := info.Get(1)
if data.ID > 0 {
go func() {
_ = tools.Gcache.Set(key, data)
}()
}
//无论数据存在不存在 都将数据缓存
cache = fmt.Sprint(data)
_ = db.Rdb.Set(context.Background(), key, cache, time.Second*5).Err()
return data, nil
})
if err != nil {
_, _ = fmt.Fprintf(w, "sf失败,缓存获取失败:"+fmt.Sprint(cache))
return err
}
return nil
},
retry.Attempts(3),
)超时的用法:
ch := sfGroup.DoChan(key, func() (interface{}, error) {
// 模拟耗时操作
time.Sleep(3 * time.Second)
return "result", nil
})
select {
case res := <-ch:
if res.Err != nil {
return "", res.Err
}
return res.Val.(string), nil
case <-time.After(timeout):
// 超时后,忘记这个 key,让后续请求重新执行
sfGroup.Forget(key)
return "", fmt.Errorf("请求超时: %s", key)
}提示
超时的用法,用的不多,了解即可。
6. 引申:HotKey
其实击穿问题在小流量场景下属于非常正常的现象,我们只要用”读更新、写删除“就必定会存在击穿和穿透问题。击穿问题真正的恐怖在于瞬发大流量压到某个缓存上,突然导致服务崩溃。而这个场景有一个专有名称:HotKey 问题(热 Key 问题)我们在本篇不过多介绍,留在 下一节 专门展开。