
0 实现缓存回溯
2025/3/1大约 4 分钟
前置操作
创建数据库:
CREATE TABLE `info` (
`id` int(11) NOT NULL,
`name` varchar(255) DEFAULT NULL,
`created_at` datetime DEFAULT NULL,
`updated_at` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;加载数据库:
package db
import (
"context"
"fmt"
"github.com/redis/go-redis/v9"
"gorm.io/driver/mysql"
"gorm.io/gorm"
)
var DB *gorm.DB
func NewDb() {
my := fmt.Sprintf("%s:%s@tcp(%s)/%s?charset=utf8&parseTime=True&loc=Local",
"training", "XczbPSTMpd8Y3FmG", "192.168.56.2:3306", "training")
conn, err := gorm.Open(mysql.Open(my), &gorm.Config{})
if err != nil {
fmt.Printf("err:%s\n", err)
panic(err)
}
DB = conn
}
var Rdb *redis.Client
func NewRdb() {
rdb := redis.NewClient(&redis.Options{
Addr: "192.168.56.2:6379",
Password: "redis_CaJKb4",
DB: 0,
})
//测试链接是否正常
_, err := rdb.Ping(context.Background()).Result()
if err != nil {
fmt.Printf("无法连接到 Redis 服务器: %v\n", err)
return
}
Rdb = rdb
}启动器:
func Run() {
//1.加载配置,链接数据库
db.NewDb()
db.NewRdb()
//2.使用go自带的http路由拉起服务
http.HandleFunc("/get_name", func(writer http.ResponseWriter, request *http.Request) {
_, _ = fmt.Fprintln(writer, "香香编程喵喵喵!")
})
fmt.Println("服务启动")
if err := http.ListenAndServe(":8081", nil); err != nil {
fmt.Println("服务器启动失败!" + err.Error())
}
}缓存回溯
所谓缓存回溯,就是先查缓存,如果不存在就去查找数据库,然后把拿到数据放进缓存里。这样下次查询的时候,可以直接从缓存获取数据。缓存回溯,目前很多生成代码工具都可以帮助生成,又快又好。我们从三个角度来看下这块逻辑。
- 从架构上来看:
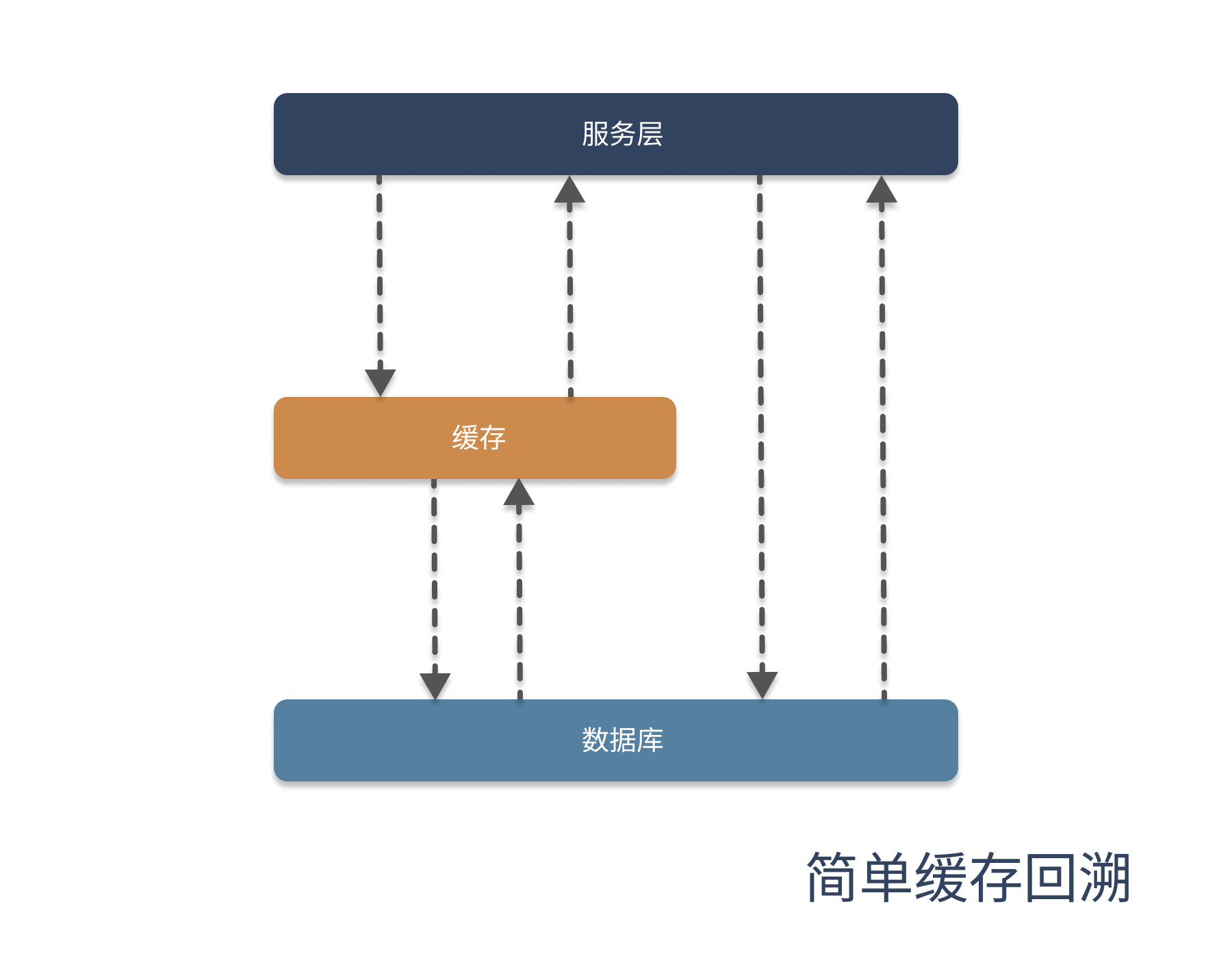
- 从流程图上来看:
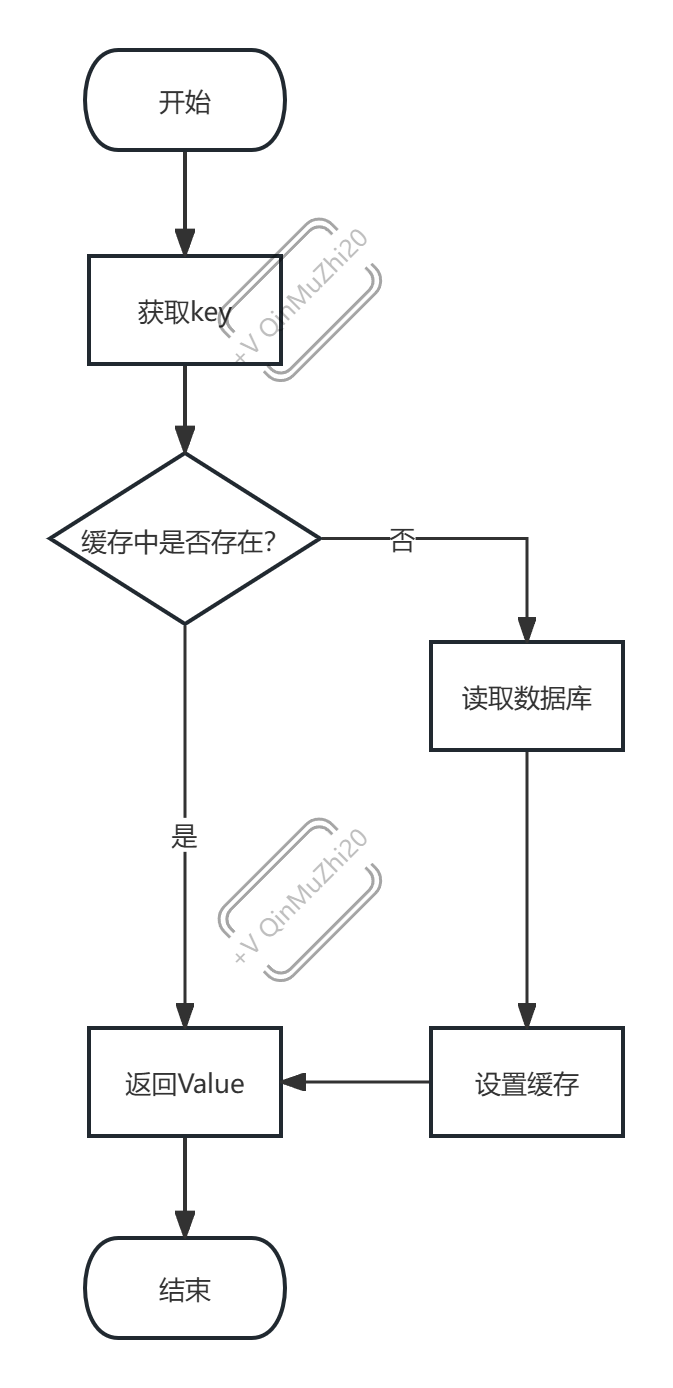
- 从代码上来看:
func GetInfo(writer http.ResponseWriter, request *http.Request) {
//必须是GET请求
if request.Method != http.MethodGet {
http.Error(writer, "只支持 GET 请求", http.StatusMethodNotAllowed)
return
}
//查看缓存是否存在
key := fmt.Sprintf("xxcode")
cache, _ := db.Rdb.Get(context.Background(), key).Result()
if cache != "" {
_, _ = fmt.Fprintf(writer, "这是查缓存的结果:"+fmt.Sprint(cache))
return
}
//查询数据库
t := db.Info{}
ret := t.Get(1)
//设置缓存ret 引申:什么是缓存穿透
if ret.ID > 0 {
_ = db.Rdb.Set(context.Background(), key, fmt.Sprint(ret), time.Second*5).Err()
}
//返回结果
_, _ = fmt.Fprintf(writer, "这是查询数据库的结果:"+fmt.Sprint(ret))
}警告
缓存回溯的优点是结构简单可靠,便于实现,能够解决大多数场景。缺点也非常明显,存在缓存击穿、穿透等问题。另外,缓存过期时长也是一个不太好把控的,需要结合业务场景来设置。
然后,我们再来看下这个接口,它仍然存在一些非常严重的缺陷,比如缓存穿透。我们会在所有方案结束后,再次尝试解决这个问题。
重要
引申:在大流量或高并发场景下,接口或多或少都会暴露问题。
缓存的终极问题:缓存一致性问题。
我们把缓存一致性问题可以分为三个等级:
- 绝对一致性。即更新数据后,无论何时何地读取必须是最新数据。这种场景比较少见,个别支付场景会碰到。
- 强一致性。更新数据后,允许极短暂的出现数据不一致,很快就能恢复。大多数业务,要求强一致性即可。
- 弱一致性。更新数据后,允许出现数据不一致,只要经过一段时间,总能保证一致。业务的普遍要求。(有时,也可以认为是最终一致性)
这里的强和弱是相对的,具体情况应当与业务场景的需要挂钩。