
3 延时双删
1. 增加一个重试
之前没有用过重试的话,可以了解下什么是重试。
go get github.com/avast/retry-go// SetBookV2 增加重试机制
func SetBookV2(w http.ResponseWriter, r *http.Request) {
if r.Method != http.MethodGet {
http.Error(w, "只支持 Get 请求", http.StatusMethodNotAllowed)
return
}
name := r.URL.Query().Get("name")
id := r.URL.Query().Get("id")
//先写数据库,然后删除掉缓存。
info := db.Info{}
idInt, _ := strconv.Atoi(id)
if err := info.Save(idInt, name); err != nil {
_, _ = fmt.Fprintf(w, "数据库更新失败!")
return
}
//将del命令改造为过期时间改为0
key := fmt.Sprintf("book_%s", id)
//默认重复10次,
err := retry.Do(func() error {
return setCache(key)
})
if err != nil {
_, _ = fmt.Fprintf(w, "缓存数据过期失败!")
return
}
_, _ = fmt.Fprintf(w, "数据更新完成,缓存已经清除!")
}
func setCache(key string) error {
return db.Rdb.PExpire(context.TODO(), key, 1).Err()
}这是一个非常鸡肋的方式。能够解决,因为网络或者 Redis 服务自身出了一些小故障,抖动之类的问题
- 整个网络或者缓存挂了,无论重试多少次,都不会有结论。
- 重试次数过多,会拖累整个接口的响应。
func SetInfoV3(w http.ResponseWriter, r *http.Request) {
// 为了便于测试,这里依然采用
if r.Method != http.MethodGet {
http.Error(w, "只支持 Get 请求", http.StatusMethodNotAllowed)
return
}
name := r.URL.Query().Get("name")
id := r.URL.Query().Get("id")
info := db.Info{}
idInt, _ := strconv.Atoi(id)
err := info.Save(idInt, name)
if err != nil {
fmt.Println(err.Error())
_, _ = fmt.Fprintf(w, "数据库更新失败。")
return
}
//这里不再更新缓存,而是直接删除数据。
go func() {
key := fmt.Sprintf("xxcode")
err = retry.Do(func() error {
return setCache(key)
})
if err != nil {
_, _ = fmt.Fprintf(w, "双写策略失败!更新缓存错误。"+err.Error())
//TODO 增加日志写入,并且是一个Level等级非常高的错误。
//可以通过监控错误日志的方式,及时发现缓存不一致现象
return
}
}()
// 向客户端发送响应
_, _ = fmt.Fprintf(w, "双写策略执行中,数据库已更新,缓存正在异步更新。")
}2. 延时双删机制
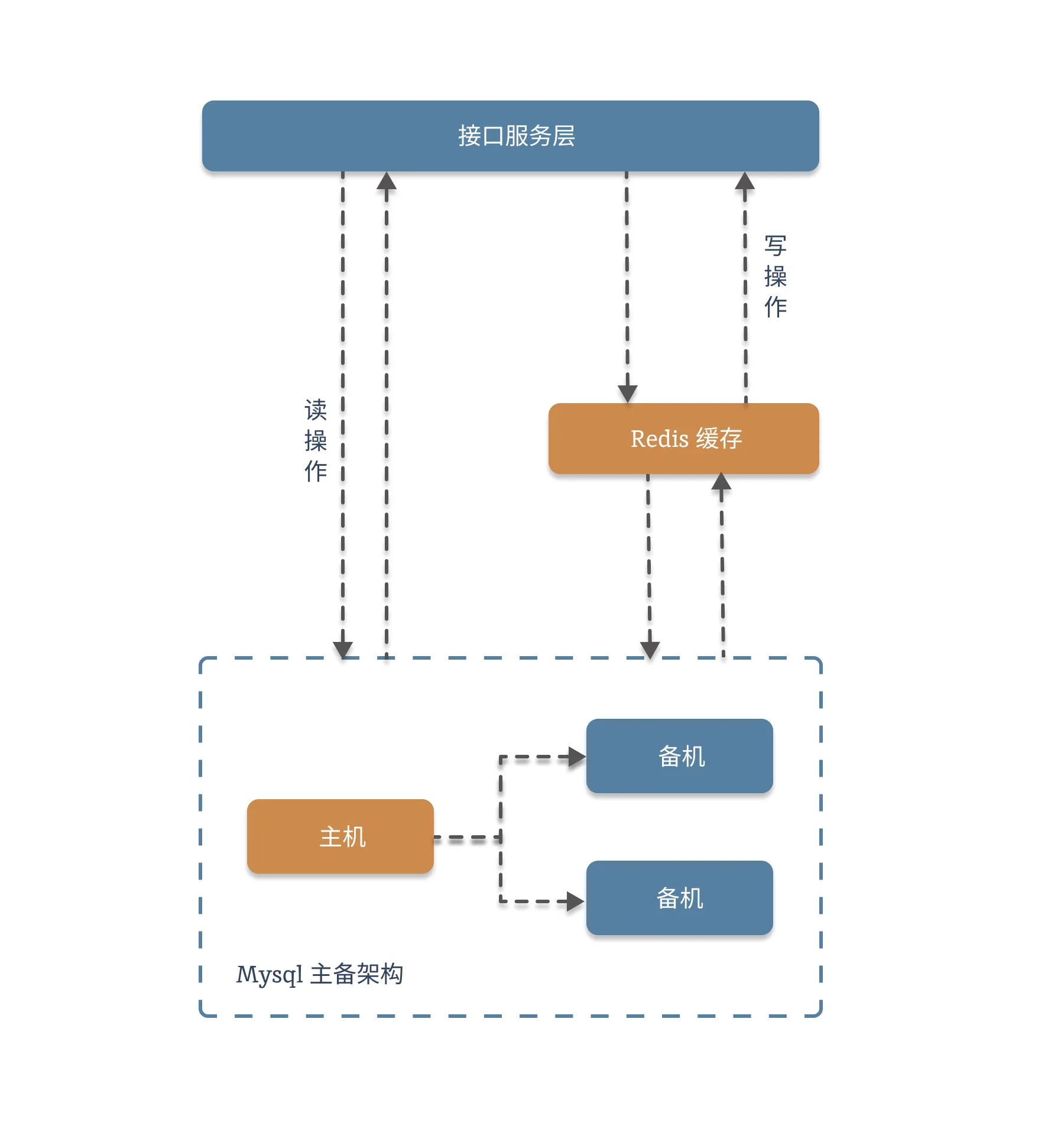
2.1. 延时双删的架构图
为什么需要双删机制?
在高并发场景下,当需要更新数据库中的数据时,为了保证缓存和数据库的数据一致性,通常会先删除缓存,再更新数据库。但在读写分离、主从复制存在延迟的系统中,可能会出现这样的问题:删除缓存后,有新的读请求进来,此时数据库还未完成更新,读请求会将旧数据重新写入缓存,导致后续一段时间内缓存和数据库的数据不一致。另外,还可能因为存在并发的现象,导致有其他用户将旧数据更新到缓存里。
我们看下这张图:
我们来看下代码:
func SetBook(w http.ResponseWriter, r *http.Request) {
if r.Method != http.MethodGet {
http.Error(w, "只支持 Get 请求", http.StatusMethodNotAllowed)
return
}
name := r.URL.Query().Get("name")
id := r.URL.Query().Get("id")
//将del命令改造为过期时间改为0
key := fmt.Sprintf("book_%s", id)
_ = db.Rdb.Expire(context.TODO(), key, 0).Err()
//先写数据库,然后删除掉缓存。
info := db.Info{}
idInt, _ := strconv.Atoi(id)
if err := info.Save(idInt, name); err != nil {
_, _ = fmt.Fprintf(w, "数据库更新失败!")
return
}
//等待一小会,再次删除缓存
time.Sleep(time.Microsecond * 10)
_ = db.Rdb.Expire(context.TODO(), key, 0).Err()
_, _ = fmt.Fprintf(w, "数据更新完成,缓存已经清除!")
}2.2. 流程图
再看下流程图: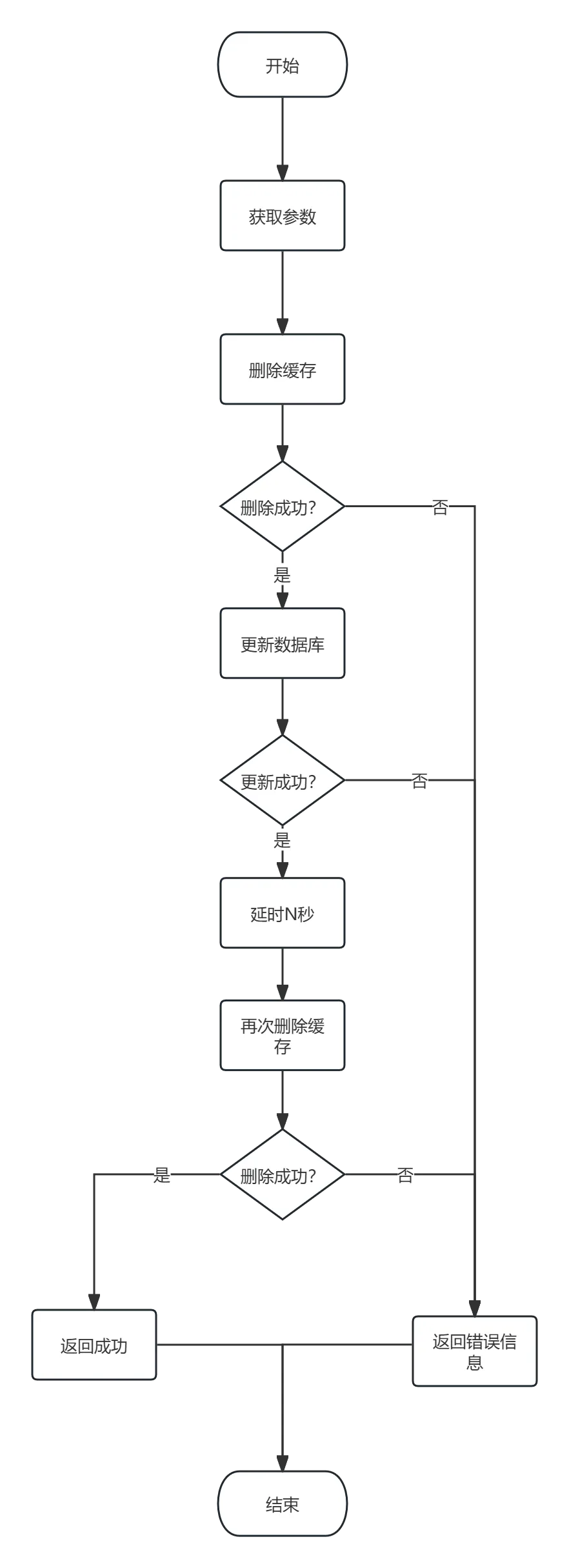
3. 为什么加上重试机制是鸡肋
我们从三个角度来谈一下重试机制在当前业务场景下为何是鸡肋。
第一,我们的目的是保证数据删除成功,而失败是一个概率事件,或者因为网络抖动,或者因为缓存服务故障。重试机制是通过多次操作,尽可能降低失败概率,并不能从根本上保证100%的成功。
第二,缓存操作是一个需要保证时效的操作。这个时效有两方面的理解:一方面是缓存的内容有一定的时效,过了这段时间可能就用不到了。另一方面,设置缓存是业务流程上的旁路,不能拖累主线业务,时间上尽可能短。触发重试,不可避免的增加耗时。
第三,缓存操作普遍是一个高频的请求,这类操作往往要求结构简单,性能可靠。向缓存操作中引入过多的三方包,或者其他逻辑,会增大出错的概率。
总而言之,我们花了大量的时间设计重试,再花大量的时间来开发和验证有效性。时间成本、人力成本并不能带来非常客观的性能收益。所以,在当前业务场景下,并不建议采用重试机制。
提示
通常情况下,我们会采用**较短的有效期+简单的更新策略,**将缓存不一致的时间尽可能的降低。
4. 延时双删的困难点
重要
延时双删的困难点,在于延时的时间定多长比较合适。
这个时间点过长,会严重拖累API的性能和响应时间。过短,可能出现主备没能同步完成的情况。而且,这个时间往往并不是一个精确的时间点,而是一个动态的区间。因此,如果要采用延时双删,需要先调查一下主备同步的时间,获得一个比较合适的延迟时间。
延迟时间往往略大于主备同步时间。