
4 异步更新
1. 缓存击穿
前面介绍的所有方法,都无法从根本上解决一个问题:缓存击穿。因此,我们在这里需要先讨论下缓存击穿的问题。
重要
缓存击穿几乎是缓存使用场景中最重要的问题。
缓存击穿是指在缓存系统中,大量请求同时访问一个在缓存中不存在但在数据库等后端存储中存在的数据 key,导致这些请求直接穿透缓存,全部打到后端数据库,从而可能使数据库承受巨大压力,甚至引发系统故障的情况。
击穿问题所带来的危害非常严重,轻则服务卡顿,重则崩溃。该问题产生的根本原因是**当前数据未加载到缓存中,**而在我们的业务场景下,最常出现的情况则是:
提示
将缓存加载至缓存,设置 5 秒过期,然后缓存过期后,出现击穿问题。
如何解决击穿问题,最简单的两个方法:数据不过期;使用互斥锁。我们今天讲一下第一种方法。
2. 异步更新
2.1. 架构图
我们先来看下异步更新的架构逻辑:
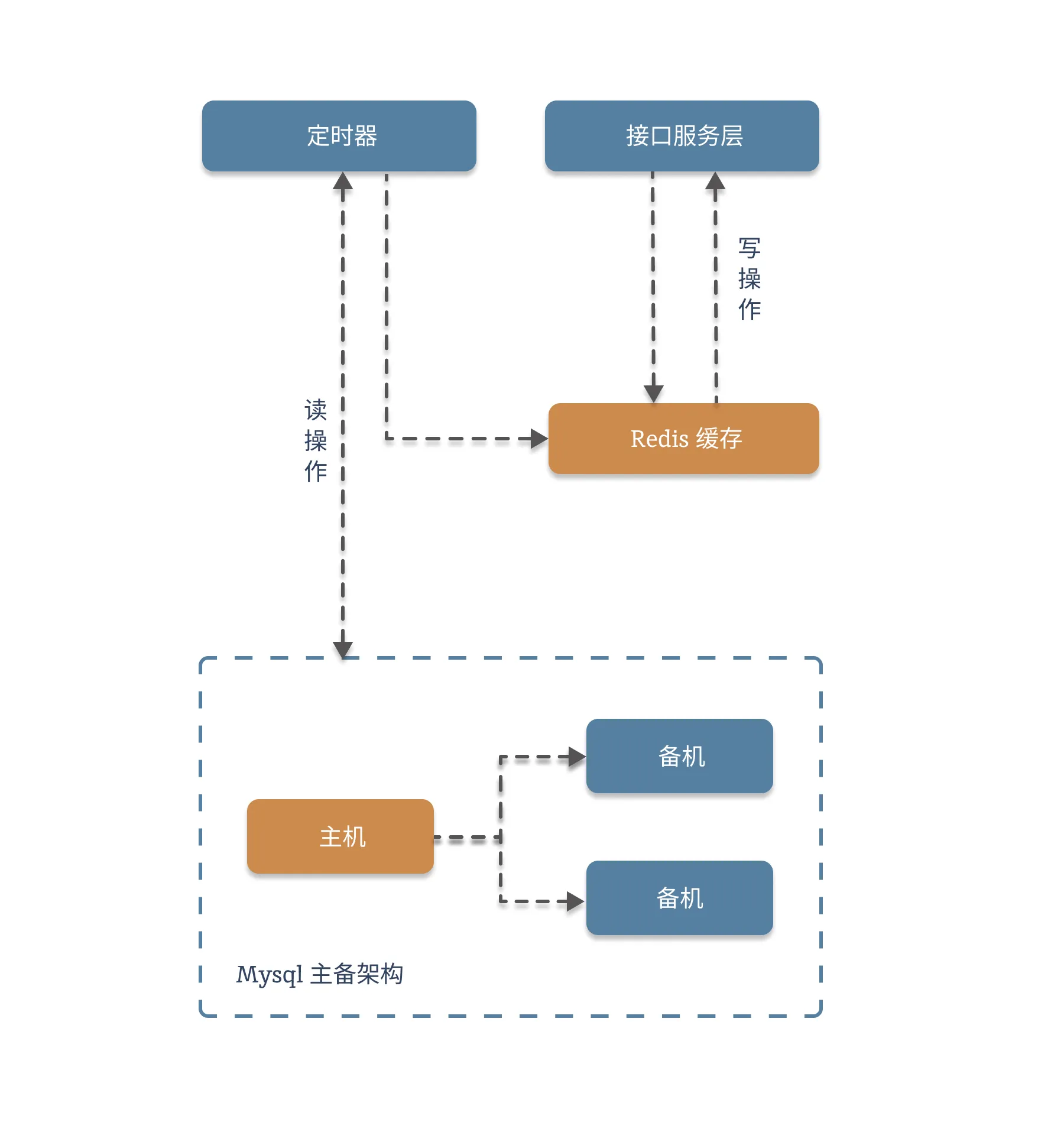
2.2. 代码块
接着来我们来看下代码:
提示
通常情况下,为了以防万一,我们的接口依然会带上缓存回溯逻辑。因此这一块,我们不做变动。
package schedule
import (
"context"
"fmt"
"time"
"training/cache/appv3/db"
)
func Run() {
go updateCache()
}
func updateCache() {
//更新缓存数据
key := fmt.Sprintf("book_%s", 1)
t := time.NewTicker(5 * time.Second)
for range t.C {
info := db.Info{}
data := info.Get(1)
_ = db.Rdb.Set(context.Background(), key, fmt.Sprint(data), time.Second*5).Err()
fmt.Println("缓存更新完成")
}
}看上去很简单,实际操作起来也确实不难。
这样子我们的缓存每过 5 秒钟,就可以定时更新缓存,接口可以一直从缓存中获取数据。这样子看上去很美好,但是依然存在非常多的工程问题。
3. 异步存在哪些问题?
异步更新缓存,存在的工程问题要远超想象。我们逐个展开:
3.1 不一致的时间有多久?
假如,我们的缓存更新周期是 10 秒钟,会不会出现这样一种情况:缓存数据一开始是 1,然后某个人把他更新成 2,然后又有一个人把他更新成了 1,这些操作,全部都在 10 秒内完成。此时,我们更新缓存还能找到 2 么?
相关信息
引申: ABA 问题
3.2. 多任务冲突怎么办
我们来看第一种情况:
func updateCacheV1() {
//更新缓存数据
t := time.NewTicker(5 * time.Second)
for range t.C {
info := db.Info{}
data := info.Get(1)
_ = db.Rdb.Set(context.Background(), fmt.Sprintf("book_%s", 1), fmt.Sprint(data), time.Second*5).Err()
data = info.Get(2)
_ = db.Rdb.Set(context.Background(), fmt.Sprintf("book_V1_%s", 1), fmt.Sprint(data), time.Second*5).Err()
fmt.Println("缓存更新完成")
data = info.Get(3)
_ = db.Rdb.Set(context.Background(), fmt.Sprintf("book_V2_%s", 1), fmt.Sprint(data), time.Second*5).Err()
fmt.Println("缓存更新完成")
}
}相关信息
此时,每个缓存的更新,还会是固定的 5 秒钟么?
我们再来看这种情况:
func updateCacheV2() {
t := time.NewTicker(5 * time.Second)
for range t.C {
info := db.Info{}
go func() {
data := info.Get(1)
_ = db.Rdb.Set(context.Background(), fmt.Sprintf("book_%s", 1), fmt.Sprint(data), time.Second*5).Err()
}()
go func() {
data := info.Get(2)
_ = db.Rdb.Set(context.Background(), fmt.Sprintf("book_V1_%s", 1), fmt.Sprint(data), time.Second*5).Err()
fmt.Println("缓存更新完成")
}()
go func() {
data := info.Get(3)
_ = db.Rdb.Set(context.Background(), fmt.Sprintf("book_V2_%s", 1), fmt.Sprint(data), time.Second*5).Err()
fmt.Println("缓存更新完成")
}()
}
}相关信息
通常都会这么写,但协程数量过多,会严重增加服务器的开销。
我们再看一种情况
func updateCacheV3() {
go func() {
t := time.NewTicker(5 * time.Second)
for range t.C {
info := db.Info{}
data := info.Get(1)
_ = db.Rdb.Set(context.Background(), fmt.Sprintf("book_%s", 1), fmt.Sprint(data), time.Second*5).Err()
}
}()
go func() {
t := time.NewTicker(15 * time.Second)
for range t.C {
info := db.Info{}
data := info.Get(1)
_ = db.Rdb.Set(context.Background(), fmt.Sprintf("book_%s", 1), fmt.Sprint(data), time.Second*5).Err()
}
}()
}相关信息
如果不同的接口缓存时间各不相同,岂不是非常麻烦?
3.3. 集群部署的困难
假如,我们的服务需要十台服务器同时运行,那么我们的定时器任务会不会在十台服务器上同时运行?
第一步,使用 nginx 反向代理,其中 9 台提供服务,另外一台只负责执行脚本操作。
第二步,在执行脚本的服务器上设置一个脚本启动器,只有这台机器会运行脚本,其他不运行。
第三步,如果有专门的网关团队和 DevOps 团队,则他们也可以协助搭建。
相关信息
看上去很简单,其实这依然是一个很不安全的方案。因为,执行脚本的服务器会在这种架构下,变成单点。如果出了故障,就非常难处理。
3.4. 缓存更新失败的严重后果
异步缓存更新失败的话,会出现比较严重的问题。总结下来主要有三种:
- 数据出现长时间的不一致现象。
- 定时器长时间执行,协程数量会越积累越多,容易拖垮物理机
- 如果接口存在回溯逻辑,可能导致缓存穿透的问题
此时,需要一个人工干预的入口,也就是后门。我们常用的方式如下:
func GetBookV4(w http.ResponseWriter, r *http.Request) {
if r.Method != http.MethodGet {
http.Error(w, "只支持 GET 请求", http.StatusMethodNotAllowed)
return
}
id := r.URL.Query().Get("id")
cache := r.URL.Query().Get("cache")
if cache == "true" {
info := db.Info{}
data := info.Get(1)
key := fmt.Sprintf("book_V4_%s", id)
_ = db.Rdb.Set(context.Background(), key, fmt.Sprint(data), time.Second*5).Err()
return
}
//redis 不存在就查询数据库
info := db.Info{}
data := info.Get(1)
key := fmt.Sprintf("book_V4_%s", id)
//如果数据存在,就写缓存
if data.ID > 0 {
_ = db.Rdb.Set(context.Background(), key, fmt.Sprint(data), time.Second*5).Err()
}
_, _ = fmt.Fprintf(w, "强制更新缓存!这是查数据库的结果:"+fmt.Sprint(data))
}相关信息
注意!这个方案极其不安全。通常只提供给 Admin 平台,绝对不能放给用户端。
3.5. 其他问题
接口参数复杂怎么办?我们再来看一种情况:
func GetBookV3(w http.ResponseWriter, r *http.Request) {
if r.Method != http.MethodGet {
http.Error(w, "只支持 GET 请求", http.StatusMethodNotAllowed)
return
}
//id := r.URL.Query().Get("id")
name := r.URL.Query().Get("name")
page := r.URL.Query().Get("page")
num := r.URL.Query().Get("num")
//先获取redis
key := fmt.Sprintf("book_V2_%s_%s_%s", name, page, num)
cache, _ := db.Rdb.Get(context.Background(), key).Result()
if cache != "" {
_, _ = fmt.Fprintf(w, "这是缓存的结果:"+fmt.Sprint(cache))
return
}
_, _ = fmt.Fprintf(w, "数据不存在!")
}异步更新:
func updateCacheV4() {
go func() {
t := time.NewTicker(5 * time.Second)
for range t.C {
info := db.Info{}
data := info.Get(1)
_ = db.Rdb.Set(context.Background(), fmt.Sprintf("book_%s", 1), fmt.Sprint(data), time.Second*5).Err()
}
}()
}我们只能缓存固定接口的参数,这个时候要如何设计:二八原则。
4. 总结
提示
如果你坚持看到这里,就会发现缓存一致性场景的根本点是:概率。
我们提供的几乎所有方案都或多或少的存在一些问题,只不过这些问题出现的概率不太一样,我们做的各种尝试,都是在努力降低出现问题的概率。异步更新存在两个方面问题:
- 一方面,可能会因为网络,或者自身硬件问题导致缓存更新失败。
- 另一方面,在部署服务的时候,会变得非常麻烦。