
5 基于消息队列
1. 前置操作
关于 kafka 的包,有三个:confluentinc/confluent-kafka-go、IBM/sarama、 kafka-go
关于这三个包的区别,可以参考一些博客。我们这里直接选择 kafka-go .
1.1. 搭建 kafka 的环境
我们这里还是基于 1panel 搭建哈,参考之前的环境搭建,直接在应用市场安装这两个应用,并且启动即可。
1.2. 创建 kafka 的链接
我们在 DB 里创建一个 kafka 的文件,然后初始化一下链接:
package db
import "github.com/segmentio/kafka-go"
var cacheWriter *kafka.Writer
var cacheReader *kafka.Reader
func NewKafka() {
cacheTopic()
cacheRe()
}
func cacheTopic() {
if cacheWriter != nil {
return
}
topic := "cache_info"
cacheWriter = &kafka.Writer{
Addr: kafka.TCP("192.168.56.101:9092"),
Topic: topic,
RequiredAcks: kafka.RequireAll, //ACK 模式
Async: true, //异步
AllowAutoTopicCreation: true, //使用
}
return
}
func cacheRe() {
cacheReader = kafka.NewReader(kafka.ReaderConfig{
Brokers: []string{"192.168.56.101:9092"},
GroupID: "test_group",
Topic: "cache_info",
})
return
}1.3. 测试一下链接
参考上面的代码,如果能跑通,就说明可以正常使用了。
第一次发送失败,可能是需要创建一下 topic。因为我们设置了自动创建,因此再试一次,即可发送成功。
2. 写数据库、写消息
绝对不会用的方案
我们先来一个弱智写法:
func SetBookV0(w http.ResponseWriter, r *http.Request) {
// 为了便于测试,这里依然采用
if r.Method != http.MethodGet {
http.Error(w, "只支持 Get 请求", http.StatusMethodNotAllowed)
return
}
name := r.URL.Query().Get("name")
id := r.URL.Query().Get("id")
info := db.Info{}
idInt, _ := strconv.Atoi(id)
_ = info.Save(idInt, name)
//写完DB后,直接写消息队列,然后再去监听消息,更新缓存
err := db.CacheWriter.WriteMessages(context.TODO(), kafka.Message{
Key: []byte(fmt.Sprintf("cache-data-%d", idInt)),
Value: []byte(name),
})
if err != nil {
fmt.Println(err.Error())
_, _ = fmt.Fprintf(w, "消息发送失败!")
return
}
// 向客户端发送响应
_, _ = fmt.Fprintf(w, "消息发送完成。")
}为什么说这个方法很弱智呢,如果你看过前面的课程了,那你肯定能发现,这不是拐了一圈, 又回到双写问题上了吗?你把兄弟当宝高么。 同时写两个,其中一个失败了怎么办。而且,这个消息总是有滞后性,能保证缓存及时更新吗?总而言之,这是个相当鸡肋的办法,我们一般是不可能去使用的。
我们把其他的代码也补一下:
package schedule
import (
"context"
"fmt"
"training/cache/appv4/db"
)
func Run() {
go readMessage()
}
func readMessage() {
for {
m, err := db.CacheReader.ReadMessage(context.TODO())
if err != nil {
fmt.Println(err.Error())
continue
}
fmt.Println(m)
}
}2.1. 架构图:
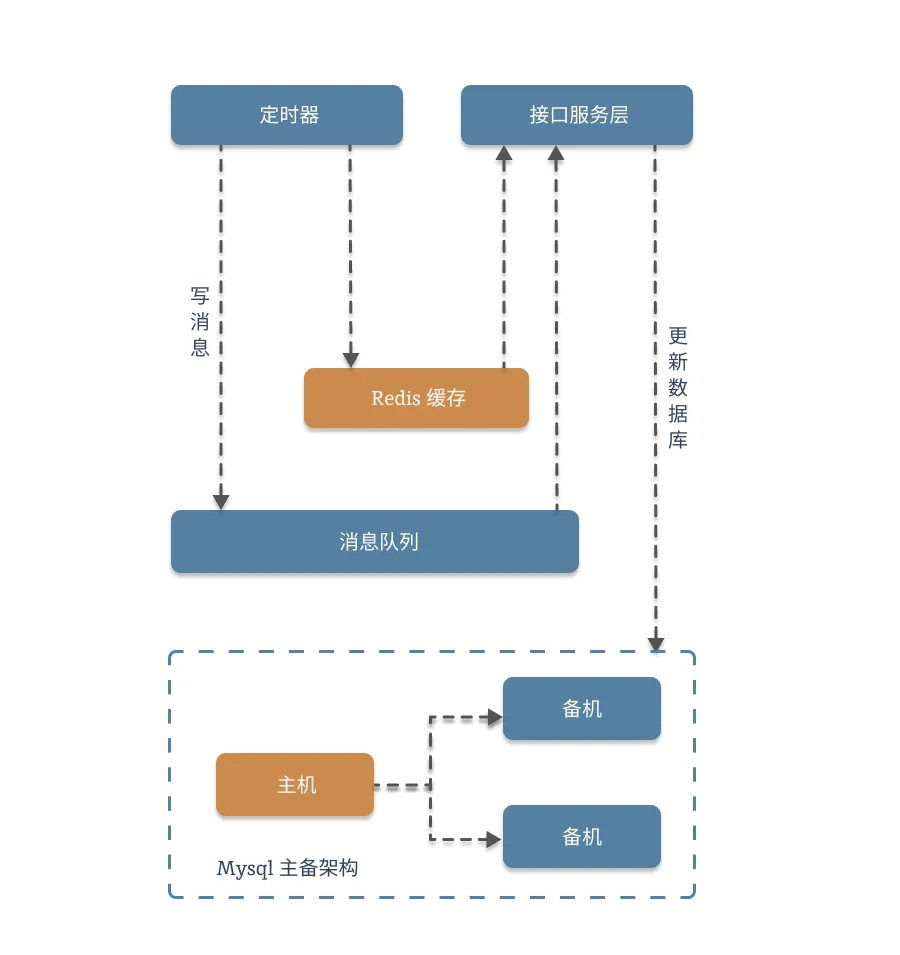
这一块,我们就没有必要设计流程图了,咱们直接看代码就行:
2.2. 代码块
写消息代码:
func SetBookV1(w http.ResponseWriter, r *http.Request) {
// 为了便于测试,这里依然采用
if r.Method != http.MethodGet {
http.Error(w, "只支持 Get 请求", http.StatusMethodNotAllowed)
return
}
name := r.URL.Query().Get("name")
id := r.URL.Query().Get("id")
key := fmt.Sprintf("book_%s", id)
if err := db.Rdb.Set(context.Background(), key, name, time.Second*5).Err(); err != nil {
_, _ = fmt.Fprintf(w, "缓存更新失败!err:%s", err.Error())
}
//写完Redis后,直接写消息队列,然后再去监听消息,更新数据库
err := db.CacheWriter.WriteMessages(context.TODO(), kafka.Message{
Key: []byte(fmt.Sprintf("cache-data-%s", id)),
Value: []byte(name),
})
if err != nil {
fmt.Println(err.Error())
_, _ = fmt.Fprintf(w, "消息发送失败!")
return
}
// 向客户端发送响应
_, _ = fmt.Fprintf(w, "消息发送完成。")
}读消息代码:
package schedule
import (
"context"
"fmt"
"strconv"
"strings"
"training/cache/appv4/db"
)
func Run() {
go readMessage()
}
func readMessage() {
for {
m, err := db.CacheReader.ReadMessage(context.TODO())
if err != nil {
fmt.Println("消息获取失败失败!")
fmt.Println(err.Error())
continue
}
info := db.Info{}
idStr := string(m.Key)
parts := strings.Split(idStr, "-")
idInt, _ := strconv.Atoi(parts[len(parts)-1])
err = info.Save(idInt, string(m.Value))
if err != nil {
fmt.Println("数据库更新失败!")
fmt.Println(err.Error())
continue
}
fmt.Println(m)
}
}2.3. 思路介绍
这个方案,其实就是把写入数据库的操作给独立了出来,让数据库停留在本职任务上,只负责数据持久化。在短时间内的业务逻辑,主要由 Redis 来提供。再这个方案下,依然存在一种情况,Redis 或者 kafka 更新失败该怎么办。
这里需要通过业务场景设计来规避,最简单就是:如果有一个数据不存在,那么就直接放弃,视为无效。
我们捋一下这个逻辑,大致可以分为一下四个情况:
- 两个都成功:正常。
- 两个都失败:失败,不入库。
- 写 消息队列失败,:失败,不再执行后续操作。
- 写消息队列成功,写 Redis 失败:双 check,视为失败。
基于此,我们需要做出一些代码上的优化:double check 和 消息幂等。
func readMessageV1() {
for {
m, err := db.CacheReader.ReadMessage(context.TODO())
if err != nil {
fmt.Println("消息获取失败失败!")
fmt.Println(err.Error())
continue
}
fmt.Println(m)
info := db.Info{}
idStr := string(m.Key)
parts := strings.Split(idStr, "-")
idInt, _ := strconv.Atoi(parts[len(parts)-1])
//double check
key := fmt.Sprintf("book_%s", idInt)
cache, _ := db.Rdb.Get(context.Background(), key).Result()
if cache == "" {
fmt.Println("缓存中不存在,此消息视为失效")
continue
}
//为接口增加幂等操作,如果关键字段没有明确的变化,则不做改动
data := info.Get(idInt)
if data.Name == string(m.Value) {
fmt.Println("数据没有变动,直接跳过")
continue
}
err = info.Save(idInt, string(m.Value))
if err != nil {
fmt.Println("数据库更新失败!")
fmt.Println(err.Error())
continue
}
}
}2.4. 完整方案
上面的代码问题很大,比如消息体非常简陋,后续操作也非常难绷。Read 操作也没有 Commit,没有充分使用到 Kafka 的特性。我们给他整一个贴近工作环境的优化。
写数据:
func SetBookV2(w http.ResponseWriter, r *http.Request) {
// 为了便于测试,这里依然采用
if r.Method != http.MethodGet {
http.Error(w, "只支持 Get 请求", http.StatusMethodNotAllowed)
return
}
name := r.URL.Query().Get("name")
id := r.URL.Query().Get("id")
//将整体数据改造为JSON
idInt, _ := strconv.Atoi(id)
data := db.Info{
ID: idInt,
Name: name,
}
dataJson, _ := json.Marshal(data)
key := fmt.Sprintf("book_%s", id)
if err := db.Rdb.Set(context.Background(), key, string(dataJson), time.Second*5).Err(); err != nil {
_, _ = fmt.Fprintf(w, "缓存更新失败!err:%s", err.Error())
}
//写完Redis后,直接写消息队列,然后再去监听消息,更新数据库
err := db.CacheWriter.WriteMessages(context.TODO(), kafka.Message{
Key: []byte(fmt.Sprintf("cache-data-%s", id)),
Value: dataJson,
})
if err != nil {
fmt.Println(err.Error())
_, _ = fmt.Fprintf(w, "消息发送失败!")
return
}
// 向客户端发送响应
_, _ = fmt.Fprintf(w, "消息发送完成。")
}读数据:
func readMessageV2() {
for {
m, err := db.CacheReader.ReadMessage(context.TODO())
if err != nil {
fmt.Println("消息获取失败失败!")
fmt.Println(err.Error())
continue
}
fmt.Println(m.Value)
info := db.Info{}
idStr := string(m.Key)
parts := strings.Split(idStr, "-")
idInt, _ := strconv.Atoi(parts[len(parts)-1])
//double check
key := fmt.Sprintf("book_%s", idInt)
cache, _ := db.Rdb.Get(context.Background(), key).Result()
if cache == "" {
fmt.Println("缓存中不存在,此消息视为失效")
continue
}
//为接口增加幂等操作,如果关键字段没有明确的变化,则不做改动
data := info.Get(idInt)
mData := db.Info{}
_ = json.Unmarshal(m.Value, &mData)
if data.Name == string(mData.Name) {
fmt.Println("数据没有变动,直接跳过")
continue
}
err = info.Save(idInt, string(m.Value))
if err != nil {
fmt.Println("数据库更新失败!")
fmt.Println(err.Error())
continue
}
}
}3. 适用的场景
我们刚才用的第二种方法,是比较常见的利用消息队列+Redis 两者共有的高性能特性,实现的高并发写操作的优化,这也是我们目前唯一的用来优化写操作的方案。它比较适用于单一写任务的场景,也就是说,这个操作的流程可以拆解,可以将写入和执行分离,利用消息队列的特性实现削峰填谷。
另外,这个方案也需要在开发过程中结局业务的边界问题,避免出现重复或者异常操作。
相关信息
引申:为什么 Kafka 性能这么高?WAL
基于消息队列有一个非常明显的优势:部署非常容易,不会像异步那样,需要固定机器,而是所有机器都可以参与工作。但是,这样做会让每台机器都需要匀出部分资源处理消息。
因此单机性能上需要降低估算,按照通常情况的 80%-90%来预估。(根据消息数量来估算,一般不会有那么多,这个值是一个相当保守的估计)