
6 基于Binlog
一般成规模的公司,普遍采用的方法。
1. 前置操作
1.1. 什么是 binlog
Binlog 是 MySQL 数据库中的一种二进制日志文件,它记录了数据库中所有的更改操作,包括数据的插入、更新、删除以及数据库结构的修改等。它有一个重要的作用是同步数据,做主从复制,当然了同步数据嘛,也不局限于 MySql,像 ES 啊也是可以做的。
它的格式有很多种,一般用作同步数据的话,会采用 Row 格式。Row 格式则是记录了每一行数据的更改前后的具体内容。比如对于一个更新操作,它会记录更新前的整行数据和更新后的整行数据。这样可以确保主从复制的准确性,避免因 SQL 语句执行环境不同而导致的数据不一致问题,但缺点是日志文件会比较大,因为要记录每一行的详细数据。
1.2. 核心中间件 Canal
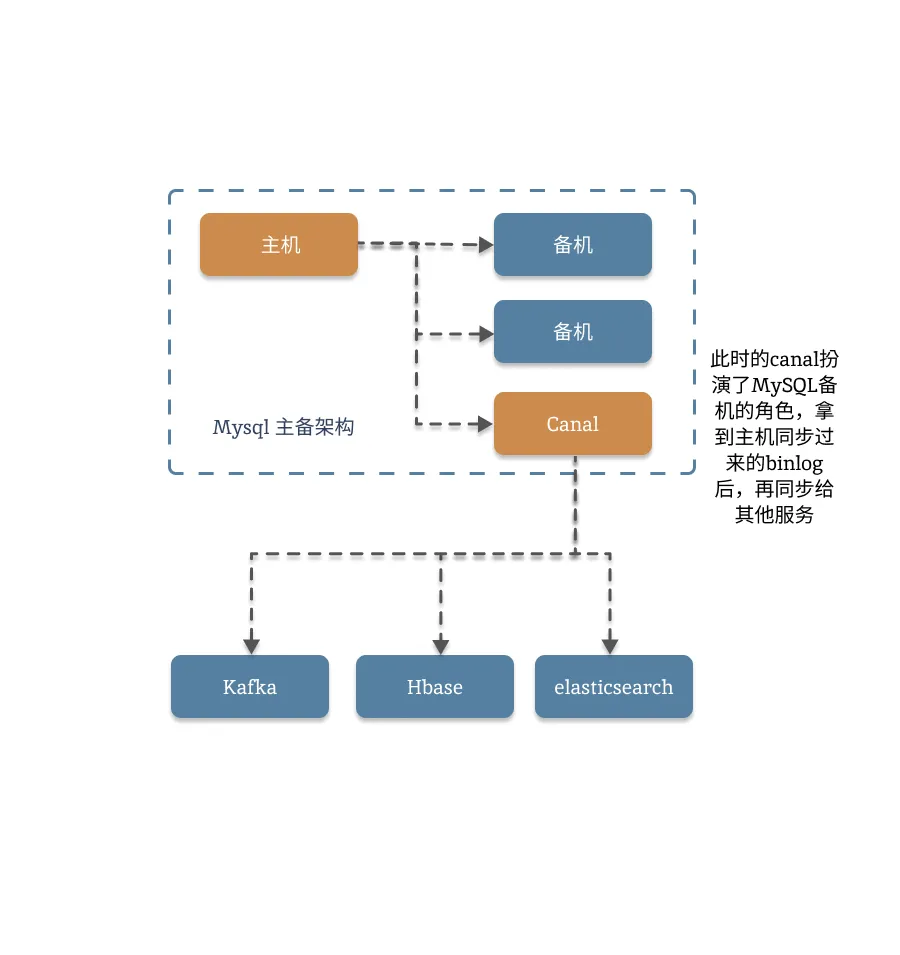
Canal 是阿里巴巴开源的一款基于数据库增量日志解析,提供增量数据订阅和消费的中间件。它是目前用的最多的,Mysql 数据同步中间件,基本上各大厂商都有支持,公司里面基本上也都在用。它的原理也很简单,Canal 将自己伪装成 MySQL 的 slave,模拟 MySQL slave 的交互协议向 MySQL Master 发送 dump 协议。MySQL Master 收到 Canal 发送的 dump 请求后,开始推送 binary log 给 Canal。Canal 解析 binary log,提取出增量数据变更信息,然后将这些信息发送到存储目的地,如 MySQL、Kafka、Elastic Search 等,实现数据的多源同步。
具体的信息可以参考:https://github.com/alibaba/canal
我们通过一张图来看下他的作用:
1.3. 模拟数据
基于虚拟机搭建 Canal 是一件比较麻烦的事儿,它需要数据库,Kafka,Java 环境等等,要想跑通整个流程是一件很麻烦的事儿。有同学感兴趣,可以用 Docker 搭一个试一下。我话说头里,都拉起来很简单,调试并且跑通就非常非常的麻烦了。
提示
因此,我们不在这里搭建环境,而是直接模拟数据走到消息队列里。(这也是日常开发过程中,自测的方法)
先定义一个这样的结构体:
type Message struct {
Table string `json:"table"`
Action string `json:"action"`
Time time.Time `json:"time"`
OldData *db.Info `json:"old_data"`
NewData *db.Info `json:"new_data"`
}模拟一个测试内容:
{
"table": "info",
"action": "UPDATE",
"time": "2025-04-30T17:36:19Z",
"old_data": {
"id": 1,
"name": "1111",
"create_at": "2025-04-30T17:36:19Z",
"update_at": "2025-04-30T17:36:19Z"
},
"new_data": {
"id": 1,
"name": "2222",
"create_at": "2025-04-30T17:36:19Z",
"update_at": "2025-04-30T17:36:19Z"
}
}2. 基于 BinLog 更新缓存
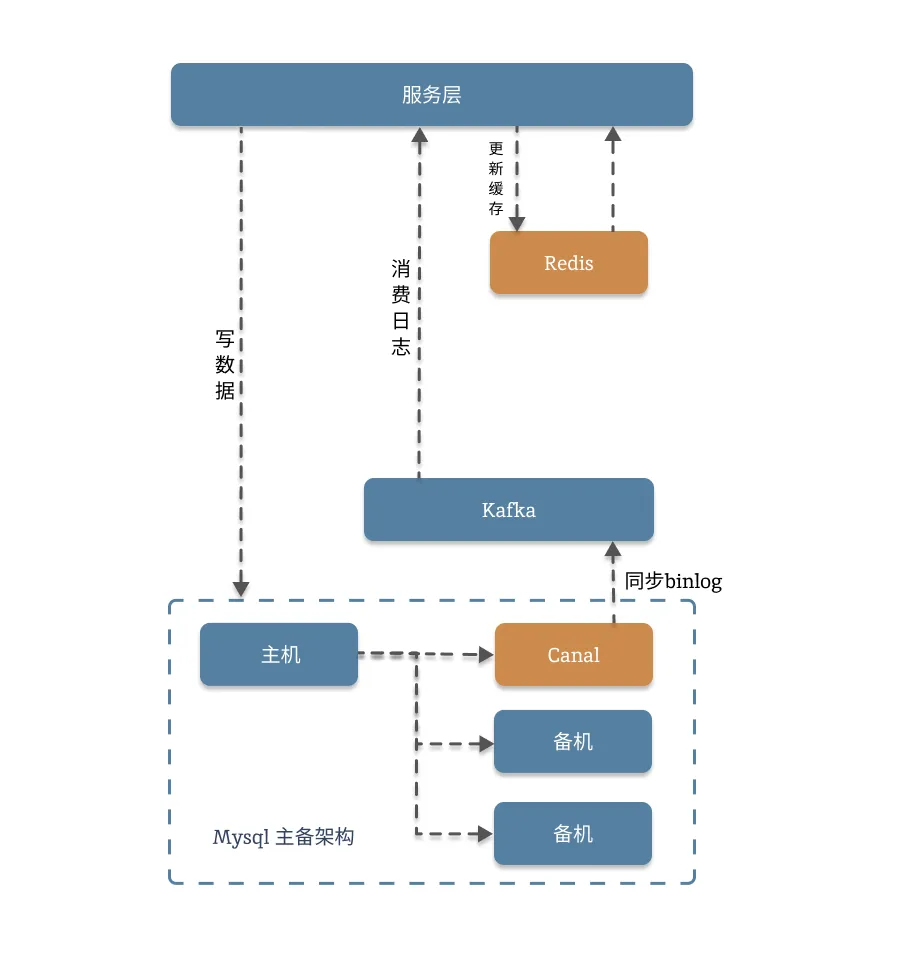
2.1.架构图
2.2. 代码块
对于此方案来说,我们只需要扮演一个消费方即可,用好读消息就能完成我们的工作,我们先来看下启动器,这一块的代码几乎没有什么明显的变化,
package schedule
import (
"context"
"fmt"
"strconv"
"strings"
"training/cache/appv5/db"
)
func Run() {
go readMessage()
}
func readMessage() {
for {
m, err := db.TableReader.ReadMessage(context.TODO())
if err != nil {
fmt.Println("消息获取失败失败!")
fmt.Println(err.Error())
continue
}
fmt.Println(m)
var mes Message
_ = json.Unmarshal(m.Value, &mes)
logic.HandleInfo(context.TODO(), &mes)
}
}业务逻辑处理:
package logic
import (
"context"
"fmt"
"log"
"qin-test/appv5/db"
"time"
)
package logic
import (
"context"
"fmt"
"log"
"time"
"training/cache/appv5/db"
"training/cache/appv5/schedule"
)
func HandleInfo(ctx context.Context, m *db.Message) {
info := db.Info{}
if m.Table != info.Table() {
//因为是异步操作,为了便于排查,都需要记录日志
log.Print(fmt.Sprintf("表名数据错误,原始数据为:%+v", m))
return
}
if m.Action == "INSERT" || m.Action == "UPDATE" {
//TODO: 增加一些前置操作
go beforeUpdate(context.Background(), m)
//更新缓存
key := fmt.Sprintf("xxcode_%d", m.NewData.ID)
_ = db.Rdb.Set(context.Background(), key, fmt.Sprint(m.NewData), time.Second*60*60).Err()
//TODO:也可以添加一些后置操作
go afterUpdate(context.Background(), m)
}
if m.Action == "DELETE" {
go beforeDelete(context.Background(), m)
//过期缓存
key := fmt.Sprintf("xxcode_%d", m.OldData.ID)
_ = db.Rdb.PExpire(context.Background(), key, time.Millisecond*1).Err()
go afterDelete(context.Background(), m)
}
}
func beforeUpdate(ctx context.Context, m *db.Message) {
fmt.Println("行数据更新前的操作")
}
func beforeDelete(ctx context.Context, m *db.Message) {
fmt.Println("行数据删除前的操作")
}
func afterUpdate(ctx context.Context, m *db.Message) {
fmt.Println("行数据更新后的操作")
}
func afterDelete(ctx context.Context, m *db.Message) {
fmt.Println("行数据删除后的操作")
}相关信息
引申:为什么要添加前置和后置操作?
数据库更新本身是一个事件,当我们将整体服务升级到微服务时,多数情况下,需要将业务驱动或者行为驱动改造为事件驱动。也就是说,整块服务会进一步的解耦,多个服务之间不再直接调用,而是以观察者的方式,彼此通过事件触发业务。这其实就是利用了消息队列的特性:通过消息或事件驱动,解耦业务。
2.3. 日志优化与测试
2.3.1. 日志优化
我们在上一个方案里使用了消息队列的可视化平台,手动向 Kafka 里塞数据,这是一个成本比较高的方案,只适合在测试环境或者线上环境联调测试时使用,我们在这里使用 TEST 来进行自测。
对于所有脚本类执行,都有一个弊端:出了问题不太好排查。这个缺陷在线上后会更加明显,因此我们一般都会在脚本类的代码中加入大量的日志断点,我们先介绍下常见的日志库:
提示
Go 常见的日志有四种:
- 标准库 log:简单场景适合使用
- 标准库 slog:能提供日志分级,需要 go1.21 以上
- 三方库 ZAP:高性能日志库,历史悠久,背靠 Uber,用的较多。
- 三方库 logrous:轻量日志库,简单好用。
在这里,我们使用 logrous 来记录日志,先在读取消息的地方加上日志:
package log
import (
"fmt"
"github.com/sirupsen/logrus"
"io"
"os"
)
func InitLog() {
//将日志输出到文件中
file, err := os.OpenFile("app.log", os.O_CREATE|os.O_WRONLY|os.O_APPEND, 0755)
if err != nil {
fmt.Println(err.Error())
logrus.Info("无法打开日志文件,使用标准输出")
}
//同时将日志输出到控制台,(线上环境可以关闭)
multiWriter := io.MultiWriter(os.Stdout, file)
logrus.SetOutput(multiWriter)
}func readMessageV1() {
for {
m, err := db.TableReader.ReadMessage(context.TODO())
if err != nil {
logrus.Error("[readMessageV1]-[err]-%s", err.Error())
continue
}
logrus.Info("[readMessageV1]-[info]-[原始数据]-%s", m.Value)
var mes db.Message
_ = json.Unmarshal(m.Value, &mes)
logrus.Info("[readMessageV1]-[info]-[转义后的json]-%s", &mes)
logic.HandleInfo(context.TODO(), &mes)
}
}func HandleInfoV1(ctx context.Context, m *db.Message) {
info := db.Info{}
logrus.Info(fmt.Sprintf("[HandleInfoV1]-[data]-%v", m))
if m.Table != info.Table() {
//因为是异步操作,为了便于排查,都需要记录日志
logrus.Error(fmt.Sprintf("[HandleInfo]-[data]-%v", m))
return
}
if m.Action == "INSERT" || m.Action == "UPDATE" {
//更新缓存
logrus.Info(fmt.Sprintf("[HandleInfo]-[data]-准备更新缓存"))
key := fmt.Sprintf("xxcode_%d", m.NewData.ID)
err := db.Rdb.Set(context.Background(), key, fmt.Sprint(m.NewData), time.Second*60*60).Err()
if err != nil {
logrus.Error(fmt.Sprintf("[HandleInfo]-[data]-[缓存数据更新失败!]-%v", err))
}
logrus.Info(fmt.Sprintf("[HandleInfo]-[data]-[缓存数据更新成功!]-%v", err))
go afterUpdate(context.Background(), m)
return
}
if m.Action == "DELETE" {
//过期缓存
key := fmt.Sprintf("xxcode_%d", m.OldData.ID)
err := db.Rdb.PExpire(context.Background(), key, time.Millisecond*1).Err()
if err != nil {
logrus.Error(fmt.Sprintf("[HandleInfo]-[data]-[缓存数据删除失败!]-%v", err))
}
go afterDelete(context.Background(), m)
return
}
logrus.Info(fmt.Sprintf("[HandleInfo]-[data]-操作类型无法匹配"))
}相关信息
引申:分布式日志平台是如何采集并存储日志的?
2.3.2. 测试
package logic
import (
"context"
"encoding/json"
"fmt"
"os"
"testing"
"training/cache/appv5/db"
"training/cache/appv5/log"
)
func initTest() {
db.NewDb()
db.NewRdb()
log.InitLog()
}
func TestMessage(t *testing.T) {
initTest()
f, err := os.Open("test.json")
if err != nil {
fmt.Println(err)
return
}
defer func() { _ = f.Close() }()
var mes db.Message
decoder := json.NewDecoder(f)
if err = decoder.Decode(&mes); err != nil {
fmt.Println(err)
return
}
fmt.Println(mes)
HandleInfoV1(context.TODO(), &mes)
}如果报错的话,有可能是循环依赖,这是一个比较棘手的问题。
警告
import cycle not allowed。解决循环依赖有一个绝招,叫做依赖注入,我们后续会教大家使用
2.4. 更好的封装
我们之前的写法并不是很好,基本上是按照最简单的手法来实现的,俗称 hardcode,硬编码。这样子很不友好:一个是不便于后续接入更多的库表日志,另一个是同一张表不方便接入更多的方法。
我们用函数链的方式来实现一个新的封装:
package schedule
import (
"context"
"encoding/json"
"fmt"
"training/cache/appv5/db"
"training/cache/appv5/logic"
)
var Handles *DBHandle
func RunV1() {
buildHandle()
go readMessageV2()
}
func buildHandle() {
if Handles == nil {
Handles = &DBHandle{}
}
Handles.Append("info", logic.InfoHandle)
}
func readMessageV2() {
for {
m, err := db.TableReader.ReadMessage(context.TODO())
if err != nil {
fmt.Println("消息获取失败失败!")
fmt.Println(err.Error())
continue
}
fmt.Println(m)
var mes db.Message
_ = json.Unmarshal(m.Value, &mes)
Handles.Do(&mes)
}
}然后是函数链:
package schedule
import (
"context"
"github.com/sirupsen/logrus"
"training/cache/appv5/db"
)
type HandleFunc interface {
SaveFunc(context.Context, *db.Message)
DeleteFunc(context.Context, *db.Message)
}
type HandleChain []HandleFunc
type DBHandle struct {
chain map[string]HandleChain //Key 为表名,数据为函数链
}
func (d *DBHandle) Append(key string, f HandleFunc) {
chains, ok := d.chain[key]
if !ok {
logrus.Error("未找到可执行函数,Key为%s", key)
}
chains = append(chains, f)
}
func (d *DBHandle) Do(m *db.Message) {
if m == nil || m.Action == "" {
logrus.Error("消息体格式错误或者Action不存在")
}
if m.Table == "" {
logrus.Error("库表信息不存在")
}
switch m.Action {
case "INSERT", "UPDATE":
d.update(m)
case "DELETE":
d.delete(m)
default:
logrus.WithField("action", m.Action).Error("未能识别的 Action")
}
return
}
func (d *DBHandle) update(m *db.Message) {
f, ok := d.chain[m.Table]
if !ok {
logrus.Error("未找到可执行函数,Key为%s", m.Table)
}
for _, h := range f {
go h.SaveFunc(context.Background(), m)
}
return
}
func (d *DBHandle) delete(m *db.Message) {
f, ok := d.chain[m.Table]
if !ok {
logrus.Error("未找到可执行函数,Key为%s", m.Table)
}
for _, h := range f {
go h.DeleteFunc(context.Background(), m)
}
return
}最后的实现:
package logic
import (
"context"
"training/cache/appv5/db"
)
type infoHandle struct {
}
var InfoHandle infoHandle
func (h infoHandle) SaveFunc(c context.Context, m *db.Message) {
}
func (h infoHandle) DeleteFunc(c context.Context, m *db.Message) {
}接着,我们用 WaitGroup 优化一下协程的使用:
func (d *DBHandle) updateV1(m *db.Message) {
f, ok := d.chain[m.Table]
if !ok {
logrus.Error("未找到可执行函数,Key为%s", m.Table)
}
wg := sync.WaitGroup{}
for _, h := range f {
wg.Add(1)
go func() {
defer wg.Done()
h.SaveFunc(context.Background(), m)
}()
}
wg.wait()
return
}// "golang.org/x/sync/errgroup"
func (d *DBHandle) updateV2(m *db.Message) {
f, ok := d.chain[m.Table]
if !ok {
logrus.Error("未找到可执行函数,Key为%s", m.Table)
}
ctx := context.Background()
g, ctx := errgroup.WithContext(ctx)
for _, h := range f {
g.Go(func() error {
h.SaveFunc(context.Background(), m)
return nil
})
}
if err := g.Wait(); err != nil {
logrus.Error("任务执行失败!Key为%s", m.Table)
}
logrus.Info("任务已经全部执行,Key为%s", m.Table)
return
}最后,我来说下这个方案需要用到的三个知识点:
相关信息
- Go Interface 的用法
- 观察者模型
- waitgroup 和 errgroup
这篇文章你可以什么都没记住,但是要记住这几个知识点
2.5. 存在哪些问题
我想,到了这里,你应该已经发现这个方案有什么问题了:这测试起来实在是太麻烦了!
是的,使用消息队列解耦业务,确实可以降低代码的复杂度,但依赖的中间件太多,又反过来会影响到开发效率。不过好的情况是,测试用的脚手架代码,只需要搭建一次,后续可以反复使用。
除了测试起来比较麻烦外,过多的组件需要更多的人力来维护和监控,也就需要更多的成本,因此小公司或者小业务,不会采用这种策略。
3. 适用的场景
注意
如果,一家公司的业务已经用到或准备用到 监听 Binlog 实现缓存一致性时,这家公司的规模已经相当了得了。
这个方案是一个实现起来比较简单有效的方案,它最大的难点是过于依赖运维团队的技术支持。没有足够的钱是养不起这么大一个团队的,哪怕是采购阿里云等云服务商的成熟产品,也需要一大笔开支。简单的讲,无论自建还是采购,都需要一大笔资金支持,小公司是没有这个实力的。
我们来盘一下,都需要哪些组件支持:
- MySQL 集群
- Canal
- Kafka
- Redis
- 日志平台
- 监控平台
。。。
仅靠几个人的小团队是无法支持这个体量的,哪怕短时间内可以充钱买到服务,后期的配置、维护和日常巡查排障都不是几个人能完成。
提示
基于 Binlog 实现的缓存一致性适合于有相当规模的业务,它普遍会和微服务结合使用,会有短时间的数据不一致,但可以有效缓解击穿和复杂业务缓存更新的问题。并且,该方法可以显著降低代码复杂性,通过消息队列的特性实现业务解耦。缺点是,依赖完整的运维平台、在调试和排障的时候有一些麻烦。
如果一个团队,超过自己的能力强行上技术方案,短期内能运行,长期来看会消耗大量的时间成本。